



In my previous post, I touched on the subject of why DevOps for Data and Machine Learning applications is more difficult and costly to implement than on traditional applications. In short…
Wow, Data DevOps looks hard!
But don’t let this deter you. Making some progress is easier than you may think…
Let’s look at traditional DevOps, and dispel a few myths…
Myth: DevOps requires a lot of tools investment.
A lot of benefits can be obtained from a DevOps approach with a minimal initial investment. DevOps can be approached progressively, and investment is scaled up as returns on earlier investments start freeing team bandwidth and allow more efficiency. DevOps should generally be approached by following the 20/80 rule: 80% of the improvements can be achieved by bridging 20% of the DevOps maturity gaps.
Myth: DevOps requires a lot of changes.
Actually true! But the majority of the change and effort does not revolve around the code or applications design, but human production, release and operation processes. DevOps requires a lot of transparency and accuracy in specifications. There is a need to be explicit about requirements, explicit about assumptions, explicit about tradeoffs. Applying DevOps methods such as “infra as code”, “config as code”, “requirements as code” may require a major shift in perspective from the teams, but doesn’t necessarily require a major effort in tooling.
Myth: So are you saying DevOps is actually cheap?
A robust DevOps approach is never cheap at scale, despite the incremental approach we have seen above when traditional applications reach the Netflix and Amazon scale. That is still true with data…
But the investment in infrastructure and tooling avoids wasting skilled employees time, improves employee engagement, reduces churn, limits management inefficiency, and alleviates the strain on support functions. If hiring skilled employees is a problem your organization is facing, then start with making sure everyone is at least using their time efficiently.
The same investment also drastically reduces defects, improves the reproducibility and optimality of the production processes, and frees resources for further efficiency and service level improvements. Ultimately, things get in production faster and cleaner, even with the extra overhead of doing DevOps.
Is Data different?
DevOps for data doesn’t significantly stray from traditional DevOps patterns and effects. However, because data impacts all functions of an organization, the context is wider, and the complexity higher.
The impact of inefficiency in the context of data is also much larger. Data Scientists spend more than 50% of their time on data sourcing and data preparation, a task they rate as the least enjoyable part of their job (CrowdFlower datascience report, 2017). Despite large investments in the field, companies report that their Machine Learning initiatives are stalled or failed in more than 80% of cases (Andrew White, Gartner, 2019). Success with data is elusive, and part of the reason is the massive maintenance cost associated with production ML systems.
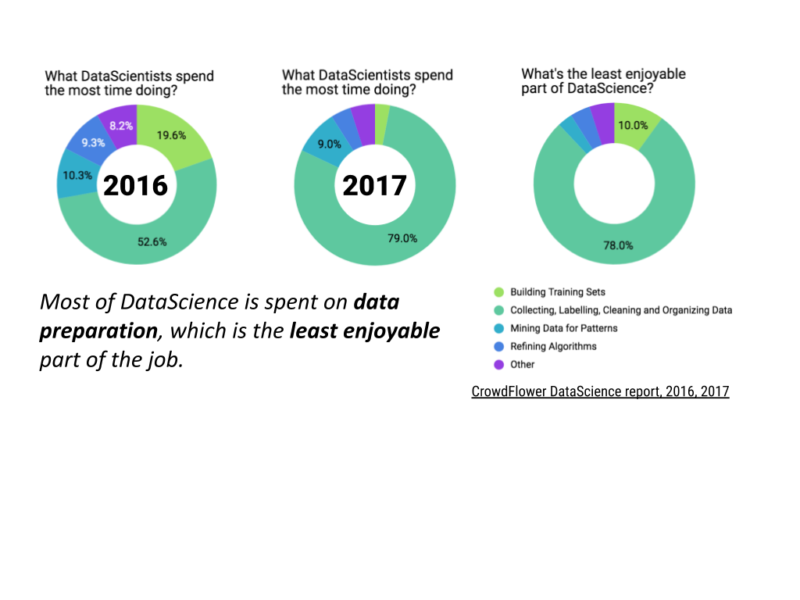
While the tools to reduce it may differ, the bulk of the effort remains, as for traditional Devops, less technical and more cultural:
- shifting people’s culture to be more systematic rather than reactive,
- shifting focus from handling problems towards automating their resolution,
- shifting application design trends from building features to building services.
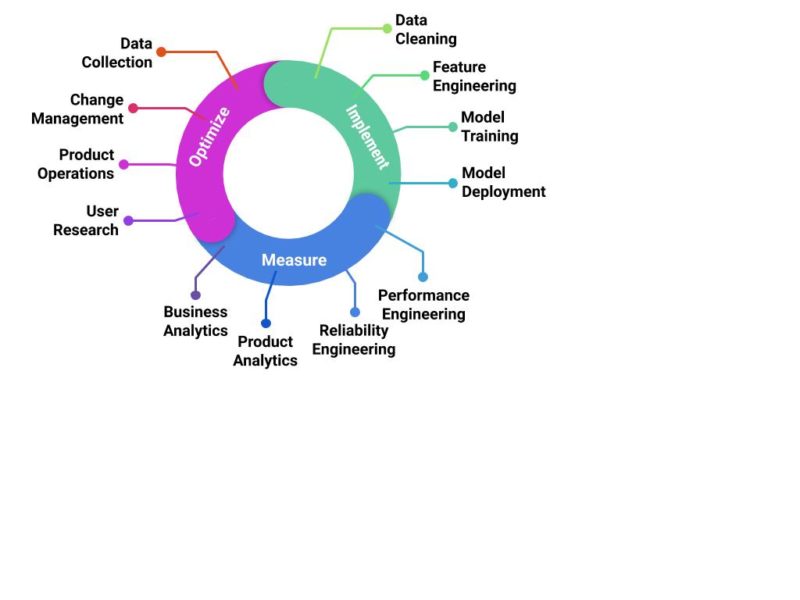
DevOps for data involves many topics and areas of the business…
Technology
- Data ingestion, accessibility, and quality
- Data discovery, inventory, and profiling
- Transformation and orchestration
- Development and deployment agility
Process and practice
- Change management, not just for code but also for data
- Knowledge management and domain expertise
- Compliance and auditing
- Collaboration and standards
Organization
- Ownership, accountability, separation of concerns
- Capability strategy, maturity, and investment rate
- Data-driven project/product management
People
- Talent, development and training strategy
- Culture and Data literacy
- Employer branding, awareness and candidate experience
Business
- Business process and data semantics
- What’s my product?
- Measure everything!
However, we will see in our next post that a few mindsets and behavior shifts can go a long way, and that best practices in the field are often just common sense.



