



Delivery Hero is one of the leading global online food ordering and delivery marketplaces. We process millions of orders per day, partnering with over 600,000 restaurants and a fleet of fantastic riders. We deliver an amazing search experience to customers in more than 45 countries and 25 languages. We power 50M+ searches per day across 4 continents.
Query expansion is an essential feature used in search engines. It improves the quality recall of search results. In this article, I will attempt to define what query expansion is, and why is it important.
If you are interested in doing this type of work on a daily basis, have a look at some of our latest Consumer Discovery openings.
What is Query Expansion?
Expanding the original search query with additional related terms is called query expansion.
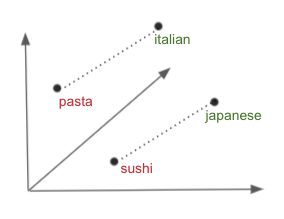
For example, the search term “pasta” expansions could be {“ italian”,” pizza”,” lasagna”}.
Why is it important?
When a user searches for a dish, restaurant or cuisine, the search term is often ambiguous and it can be difficult to comprehend what the user is searching for. This might impact the results we return. As well as that, in some locations, there might be no restaurants serving the dish the user is looking for. In order to tackle these problems, we have expanded the entered search term with semantically related terms and this has improved the recall rate and substantially decreased the number of sessions that return zero results.
So, how do we solve this?
One of the state of the art techniques to handle these kind of problems is through word embeddings.
What are word embeddings?
A word embedding is a learned representation for text where words that have the same meaning have a similar representation. It is one of the feature engineering methods in NLP problems. There are a few other approaches as well, for example, to represent the text in the form of numbers like Bag of words, TF-IDF scores etc.
Bag of words is defined by a table that contains word frequencies from a dictionary, generated by considering all the terms in the project. The word list is commonly orderless and doesn’t consider the laws of grammar. The columns represent word frequencies, and rows represent the files or documents which contain them, thus bag of words.
Let’s take a look at an example to help us understand.
Document 1: Pizza with chicken is delicious.
Document 2: The chicken burger is disgusting.
The dictionary created may be a list of unique tokens (words) in the corpus =[‘chicken’,’pizza’,’burger’,’delicious’,’disgust’]
Here, D=2, N=5
The 2 X 5 count matrix M will be represented as:

One limitation of the bag of words approach is that it treats every word as equally important, whereas intuitively we know that some words occur frequently within a corpus. We can handle this by TF-IDF (Term Frequency- Inverse document frequency) where term frequency counts the number of times a term occurred in a document, and we count the number of documents in which each word occurs. This can be called document frequency. We then divide the term frequencies by the document frequency of that term.
The above two approaches usually work in some situations but break down when we have a large vocabulary to deal with because the size of our word representation grows with the number of words. What we need is a way to control the size of our word representation by limiting it to a fixed-size vector. That’s exactly what we do using word embeddings. The idea is if two words are similar in meaning, they should be closer to each other compared to words that are not. And if two pairs of words have a similar difference in their meanings, they should be approximately equally separated in the embedded space.
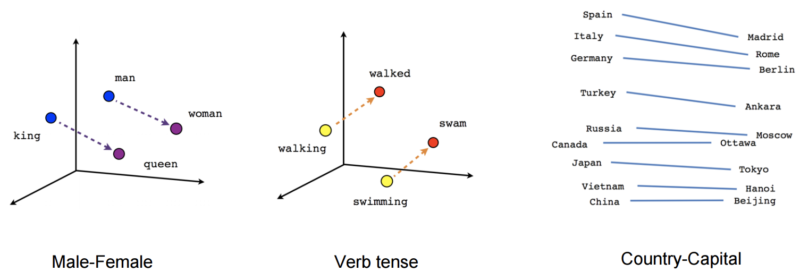
One of the classic examples for word embedding is:
“King” – “Man” + “Woman” = “Queen”
What libraries can I use to create the word embeddings?
There are several libraries available to perform the word embeddings, but these are the popular ones.
- Google’s Word2Vec
Word2Vec is perhaps one of the most popular examples of word embeddings used in practice. As the name Word2Vec indicates, it transforms words to vectors. But what the name doesn’t give away, is how that transformation is performed. The core idea behind Word2Vec is this: a model that is able to predict a given word, given neighbouring words, or vice versa. Predicting neighbouring words for a given word is likely to capture the contextual meanings of words very well.

The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence.
Word2vec can utilize one of two model architectures to produce a distributed representation of words: continuous bag-of-words (CBOW) or skip-gram.
CBOW works by attempting to predict the likelihood of a word given a context. A context may be a single word or a group of words. The objective of the CBOW is to negative log-likelihood of a word given a set of contexts. See images below:

CBOW Architecture

The topology of skip gram is the same as that of CBOW. It simply flips the architecture of CBOW on its head. The aim of skip-gram is to predict the sense of a word given its meaning.
Skip gram architecture

The difference between CBOW and skip-gram can be summarised in the following images:

- Stanford’s GloVe
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
- Facebook’s fastText
FastText is a library for the learning of word embeddings and text classification created by Facebook’s AI Research lab. It breaks words into several n-grams (sub-words). For instance, the tri-grams for the word apple is app, ppl, and ple (ignoring the start and end of boundaries of words). The word embedding vector for apple will be the sum of all these n-grams. After training the Neural Network, we will have word embeddings for all the n-grams given the training dataset.
How do the results look?

In the above 2D plot we can see that search terms which are related are grouped together ( {“pizza”,” Italian”,” pasta”}, {“healthy”,” salad”,” green”,” vegan”}, {“sushi”,”japanese”,”makisan”} etc )


So, what are our next steps?
We are building a query understanding service to solve most of the challenges related to search. Query understanding is the process of inferring the intent of the user by extracting semantic meaning from the search query keywords. Query understanding methods generally take place before the search engine retrieves and ranks results. Query expansion is just one of the query understanding techniques. We are also working on various methods like intent classification, spelling correction, multi-lingual tokenization, and so on.
Thank you, Bhaskar for your insight! Our Consumer Discovery tribe is always looking for more heroes, so check out some of our latest Consumer Discovery openings, or join our Talent Community to stay up to date with what’s going on at Delivery Hero and receive customized job alerts! Looking for more related content? Take a look at Bhaskar’s tutorial on our Youtube Channel “Query understanding“.




