



In the world of test-driven development, load testing is often overlooked. Here we would like to make a case to give load testing the attention it deserves and provide some useful tips based on our experience in Delivery Hero Engineering.
What is load testing?
Simply put, load testing is the process of putting demand on a system and measuring its response. There are different specific types of load testing, for example, stress, soak or performance, but here we will be writing more broadly about the topic and what’s involved.
Why would you spend time on load testing?
In a complicated architecture, perhaps with multiple microservices or in a distributed system, the effect of any change can be very large. Perhaps a change seems quite small but the knock-on effect can be unimaginable and often not evident until it’s too late. Couple this with an environment where the rate of change and growth is very high and you can guarantee that load testing will give you insights and assurance that simple unit or integration tests will not.
We believe everyone should be able to answer these questions about their application:
- At what load does my application performance start to degrade?
- Why does it degrade?
- Does it degrade linearly?
- At what level does my application completely stop working?
Some other use cases for load testing include reproducing a specific problem, stressing a specific component, stressing a whole system, saving money by finding unused capacity or performance hot-spots, testing the effect of infrastructure changes, detecting performance regressions and performance tuning.
What makes a good load test?
Most of the time you will be aiming for realism. The load generated in your test needs to be like the real load your application receives. This sounds simple but can be quite tricky at times. For example, how do you even measure realism? Throughput level? Types of requests? The number of users? Even small deviations away from realism in your test can render the results meaningless, especially when different types of load use different parts of your infrastructure.
For example, perhaps one type of request always requires a very expensive database transaction but another type would be cached. Both requests need to be in your load test but at a representative throughput.
To achieve a good level of realism, often you need to measure some attributes of the real traffic to emulate. Depending on your application these could include:
- Types of HTTP requests, e.g. GET, PUT, POST
- API endpoints called, e.g. /login, /create, /search
- Data payloads, e.g. the data structure and content consumed for your application
- Pages loaded, e.g. /home.html, /login.html, /my-slug/my-page.html
Also very important is not just the above attributes but the distribution of their frequency. For example, a user will likely only call a /login API once per session, so your load test needs to reflect this. Collecting this data about your traffic will usually come from a monitoring or logging system. Currently, it’s common for teams in Delivery Hero to observe application transaction frequency in an APM solution, such as New Relic, and then make a load test replicate that distribution.
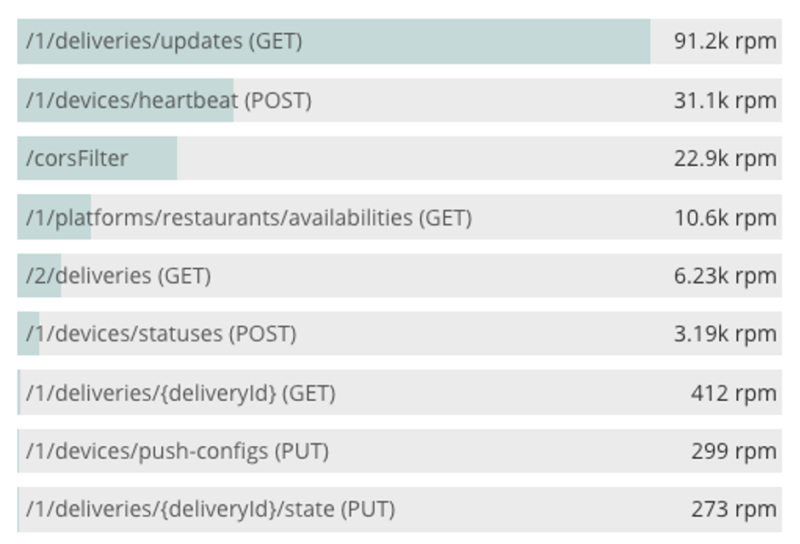
Alternatively, you could collect application logs and with some text processing, count and produce a distribution of request types to replicate in your load test.
Tools
Tool selection is very important as it can shape the types of tests you will be able to do.
Basic tools such as wrk, ab and siege can be used to generate a lot of HTTP requests efficiently. Basic options like adding HTTP headers and a payload are possible but no logic is supported.
Intermediate tools like goad or jmeter give you more options around distributing the load generation and some logic in the test. Some people might disagree with putting the venerable jmeter in this section but with its terrible UX and clunky XML files, it belongs here!
Advanced tools are actually more like frameworks for specific languages and are as flexible as their language can be. These include:
If you want to achieve realism in your test and have a complicated system, simply generating predefined HTTP requests is not good enough. Often replicating a real flow that a user or process takes is required and these types of tests will need an advanced tool like the above.
There are also numerous cloud-based tools and services.
Measurement and observation
Measurement during a load test is extremely important and will vary in toolsets, metrics, and components depending on the application being tested, but ultimately it’s about performance and for most applications, this usually means a response time of some sort.
You will need to know the infrastructure used by your application. Does it use a relational database? Does it use a cache? Does it call other applications? Can it autoscale? You will need to be aware of every constraint your application has to know where the limit is and why it’s there. This will likely require observing many metrics about your application and its dependencies.
What metrics are important will depend on what the resource is but we can make some generalizations about what is important:
- Latency overall: don’t use average, look at percentiles like P95, P99
- Latency for specific transactions
- Throughput: RPS/RPM, or a business metric like orders/minute.
- Error rate: request failures, HTTP 500 errors
- Hardware: CPU, memory, network
- Data storage: query rate, cache hit/miss, connections, locks, buffers, queue depth, IOPs
Some of the monitoring tools we use at Delivery Hero are:
- Prometheus and exporters for all types of data
- New Relic for APM
- Cloudwatch for AWS resources
- Stackdriver for GCP resources
- Datadog for logging and APM
- Sysdig for system metrics
An example
Here we will describe a load test that we would use for a Delivery Hero platform and show what component is tested by each step:
- Load home page (frontend)
- Load login page (frontend)
- Call login API (microservice)
- Save login token from the previous step for all future requests (in load test)
- Select a random post code (in load test)
- Load restaurant list page for post code (frontend)
- Call restaurant list API with post code (microservice)
- Save random subset of restaurants from the previous step (in load test)
- Load each restaurant menu page (frontend)
- Call menu API for each restaurant (microservice)
- Select 1 restaurant (in load test)
- Call order API, fill the cart with menu items until min order value is reached (microservice)
- Load cart page (frontend)
- Call order API and complete the checkout process (microservice)
In this test, some steps will depend on previous steps and stateful data is saved to be used later. As such, this complexity is only achievable using one of the advanced load test tools listed previously.
Pitfalls and tips
Often it’s hard to load test an application in isolation. For example when a service depends on another service, that depends on another service and so on. This rapidly increases complexity so often we will mock dependencies of an application using a tool like WireMock as this allows us to choose the boundaries for a load test. This tool supports advanced features to help with realism like callbacks, custom delays, generating UUIDs, generating random data payloads and more.
Scaling a complex load test can also be challenging. Generating 10-20K RPM from your laptop is doable but 200K+ RPM requires some extra resources. And 1M+ RPM might require some extra engineering. Your options here will depend on your tools, for example, Locust supports a typical master/slave arrangement that allows for horizontal scaling to increase load. Some of the other tools reserve their scaling features for paid support so it might require a more DIY approach.
If you’re working on a modern system then it’s likely you’re running on a cloud. In this case, it’s an obvious assumption that your limit will simply be CPU: it’s the most expensive resource in the cloud therefore it’s least likely to be wasted. But you would be surprised at the number of problems and debugging that is required before money is the only thing holding your application back. Often you can’t simply scale up to achieve your desired load and here are some unexpected limits we have encountered:
- Running out of an EC2 instance type in a region
- Running out of burst IOPs and CPU credits
- Stolen CPU on cloud instances
- Not enough IP addresses in subnet
- Disk space and open files limits in OS
- Elasticache network bandwidth limit due to application storing too much data
- Rate limited 3rd party APIs, e.g. payment processors and geocoding
- Non-autoscaling resources, e.g. queue consumers
- Getting blocked by CDN or WAF provider
- Thread starvation and locking issues
- Connection limits and timeouts at various levels
- Not enough resources for the load test itself
And of course, we’ve made (and learned from!) many mistakes along the way:
- Running against an empty database gives an unrealistic performance
- Load testing in isolation can be unrealistic
- Not load testing in isolation can be too complicated
- Load test and production environment differences render results meaningless
- Not saving results from load tests
- Accidentally sending emails and SMS notifications from load test
- Accidentally load testing a production system
- Incurring huge costs from logging, scaling and not removing infrastructure after
I hope this article has given you some idea of the benefits and also the complexity involved in good load testing. It’s a worthy pursuit but like many things in life and technology, it takes some effort to get right. As always, if you’re interested in joining the team, have a look at some of our open positions:




