



Hello dear readers, as a junior engineer I have always wondered how we manage and deploy our services in our organization. Note that this will be a gentle introduction by someone with little infra experience and not an advanced deep dive. If you think that might bring a little bit of value to you, do read on ٩(˘◡˘)۶.
Note that this article is written in the context of how services and resources are managed in Pandora. Pandora is the internal name for Delivery Hero’s largest platform, powering Foodpanda, Foodora, and other brands.
What is Terraform?
Not knowing where to start, I began by trying to figure out what Terraform is (because our Pandora Infra Terraform repository literally says “This repository was created to facilitate provisioning infrastructure on Pandora by using Terraform and Atlantis.”).
So I went on YouTube and randomly found this video where they explained that Terraform is a declarative way to do infrastructural provisioning (define desired end-state of your infrastructure rather than specifying a sequence of actions to reach that state). It is open-source and you define and manage your infrastructure configurations in files that can be version-controlled, reviewed, and shared like any other code.
The video then further explained what infrastructure provisioning means. They explained that if you want to spin up several servers to deploy your microservices (as docker containers) that make up your app, you’d have to go on and do stuff like:
- Create private network resources,
- Create EC2 instances,
- Install Docker and other tools,
- And so on
So naturally, I tried to poke around our Terraform repositories we have in Pandora to see in code how this is done. But weirdly, I couldn’t find any of our apps and services getting managed by Terraform.
Note: Will come back to give an example of how Terraform is used after the next section.
How do we run and deploy our apps and services?
That is when I found out that we don’t use Terraform to manage our services, we use Kubernetes instead.
Q: Why don’t we use Terraform to spin up servers?
A: If a server goes down, Terraform is not going to spin it back up. Kubernetes does different things like auto-scaling, load-balancing, monitoring of health of the servers, etc.
In Pandora, we use EKS (Amazon’s Kubernetes service) so I’m just gonna use Kubernetes and EKS interchangeably from this point on. Kubernetes orchestrates the deployment of these containers on EC2 worker nodes.
What is EKS? What are containers? What are worker nodes?
Not gonna lie, at this point, I felt mildly overwhelmed because it just felt like tons of unfamiliar terms getting thrown at me, and I still haven’t seen the code that helps me better understand what Terraform does. I apologize for not fully explaining the previous section but please bear with me while I briefly explain EKS, containers and nodes in the following section.
What’s Docker and Kubernetes?
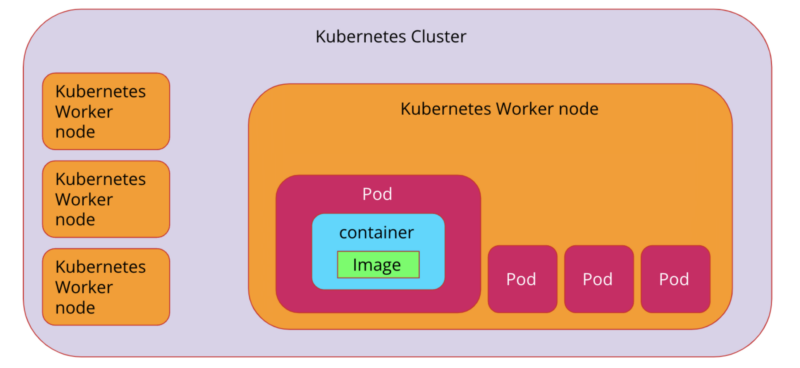
At the lowest level, the Docker container is the instantiation of the Docker image. There are different types of containers but Docker is the most common. A container is a snapshot of an operating system and is a thing that runs on a server – it has enough components of an operating system to enable applications to run on it (it is a package of all of the things you need to run an application, kinda like a package.json but at an OS level). A Docker file will build the image.
Next, a pod configures and runs containers inside a Kubernetes cluster. Multiple pods can run on a single worker node. Pods are aware of the resources provided by a worker node (a worker node is where the pods run and you can think of it as a server like an EC2 instance that is capable of running Docker containers).
EKS’s job is to run pods on all these worker nodes and expose them to each other via the internal cluster networking. A Kubernetes cluster can have multiple worker nodes and will control how many worker nodes a cluster should have. This means that Kubernetes is in control of load balancing and auto-scaling of pods. If a worker node has 1GB of RAM and a pod needs 100MB RAM, EKS won’t run more than 10 pods on a worker node.
Q: How do we create this EKS cluster?
A: Usually the infra team will be in charge of cluster upgrade exercises which provision a new EKS cluster, traffic switch and decommissions the old EKS cluster. This means that the cluster is already provisioned and available for us to use. To focus on the main topics we’re exploring here and because I don’t exactly know how they do it (lol) we shall just assume it’s there for us to use.
How do we deploy a new service/app?
We recently changed to a new self-serviced way of deploying a new app. There are a few prerequisites that we have to meet like setting up metrics and logs (so we can monitor relevant information through DataDog) and specific commands we run to set up basic configurations for our apps. However, in this article, I will briefly cover what happens in general instead of the specific steps we do.
We use an internal tool called Morty to deploy software in Pandora. We can access it via a UI or by calling its API. To ensure the successful deployment of an app, we have to have these three things:
- The app or service
- Configurations for it are created
- The docker image exists
The first step in the pipeline is the creation of Docker images. The drone.yaml file is in the repo of each application. In our case (one of the apps), we run linter, run tests, and build and push the docker image to Google Container Registry. This process is automated using Drone, a Continuous Integration system and is triggered each time we make a commit.

We now have a Docker image after this step.
Now, we need configurations for our app/service. In Pandora, we store our configurations in a repository that will run pipelines after you create a tag to create a configuration for your application and the Drone pipeline will store the configs in a S3 bucket. Secrets can be referenced from the parameter store and point to it in the config spec file.
What’s missing is to onboard our app/service to our helm charts repository. In it, we specify things like resources (limits and requests), autoscaling, service ports, etc. Note that a helm chart is used to package a service to run on Kubernetes – for example, service/app A needs 200 MB of RAM and needs to expose these network ports.
Argo (a declarative, GitOps continuous delivery tool for Kubernetes which automates the deployment of the application to the Kubernetes cluster) applies all the resources in the cluster and it’s now in the cluster managed by EKS at this point in time.
Finally, we use the Morty UI to patch the correct image and configuration:

Very cool, but at this point in time the original question of what Terraform is and how it is used is still unanswered. That is when I realized that:
We use Terraform for managing network resources, topics, queues, DynamoDB and services you don’t want to containerize/can’t containerize.
Example of how Terraform is used:
Imagine if your application or service needs to use a DynamoDB or an SQS queue. To set that up, one option is to go to the AWS console, click DynamoDB (or SQS respectively), then go through the steps to create them etc. That is fine and manageable in a smaller organization or for a personal project. However, in Pandora, if the infra team allows that, things will get out of hand (wrong configs, setup, values etc.).
So, we go through a “centralized” place to do this – and that is through a “Terraform Repository”.
We use Terraform, Terragrunt and Atlantis together.
Terragrunt is a thin wrapper for Terraform. It adds extra functionality and simplifies the management of complex Terraform configurations and workflows.
Atlantis acts as a pull-request automation tool for Terraform. Atlantis integrates with version control tools like Github, allowing you to apply your Terraform configurations using pull requests. When you create a pull request, Atlantis automatically detects changes to the infrastructure code and performs a plan and/or apply operation based on the defined workflow.
Basically, it’s still using Terraform, Terragrunt and Atlantis are like “booster packs” — no need to dive too deep into Terragrunt and Atlantis.

Say, we want to create a new DynamoDB for our app. We just have to go to our Pandora repo to specify the source, env, table_name, etc and comment and run Atlantis plan in the PR. We also have a terraform plugin that describes how DynamoDB is created (we abstract it out as a reusable module). When you run Atlantis plan, it will run terraform plan, and will take the module and run it.
After this step is run, we get infra team’s approval. Next, once we comment and run atlantis apply (which applies the generated plan we got from running atlantis plan), the DynamoDB will be created in AWS. At this point in time we can head over to the AWS console to check that it is indeed created there.
Summary/TLDR
- Infra stuff is confusing
- External Resources/Services like AWS’s DynamoDB, SQS -> use Terraform
- Internal Resources/Services like our own microservices, workers -> use Kubernetes
Thank you for reading this article. I hope it was a teeny bit helpful and interesting (or at least entertaining) (ɔ◔‿◔)ɔ ♥
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.



