



At first, Baemin was created as a single project.
Our orders grew rapidly, with the growth charted out as a J curve, and the traffic naturally grew as the number of orders increased.

The exploding traffic was too much to handle with a database on a single system, so Baemin had to endure a long period of time where it was riddled with errors.

Hence Baemin has attempted to switch to a microservice. The microservice was completed on November 1, 2019, with the separation of all systems, and we got the system stabilized.

This is from Baemin’s microservice journey by Younghan Kim presented at “WOOWACON 2020.”

Baemin switched to a microservice and welcomed the era of event-based architecture.
Many companies and developers both at home and abroad are talking about MSA, including the “microservice journey” at WOOWACON 2020. From a macroscopic perspective, it seems event-based architecture is now a somewhat familiar concept, but event-based architecture is still a new thing from a microscopic perspective looking at one system.

So, we’d like to introduce how Baemin is handling event-based architecture on one system with this post.
What to publish as events?
Why does being event-driven get mentioned when we talk about MicroService Architecture (MSA hereafter)?
It’s related to loose coupling among MSA’s core keywords. Each microservice can reduce dependency and impact on other systems by being loosely coupled, and a highly cohesive system can be created by each system focusing on its own purpose. An Event-driven approach helps with this.
To help with your understanding, let’s take an example of the relationship between two domains, Baemin’s member and family account.
There’s a policy that “if a member’s identity verification is initialized, the member must be withdrawn from the family account service.”
This policy is shown in the codes below.

The logic for withdrawal from the family account service is deeply involved with a member’s identity verification removal logic. The two have a strong coupling.
As we are reorganized as a microservice, two domains have been separated into different systems; the member system and the family account system. At this time, a physical separation occurs for the two domains that used to exist in one system.

By this physical system separation, the code-level calls are now synchronized HTTP communication. However, the intention of calling the target domain remains, so it’s hard to say that the coupling is loose with just the physical system separation.
What comes to mind easily when we think of how to remove physical dependency is the asynchronous method. Typical asynchronous methods include HTTP method via a separate thread and a method using the messaging system.
HTTP requests are made through separate threads separated from the main flow.

It’s done on a separate thread, so the direct coupling from the main flow can be removed. However, the intention of calling the target domain still remains, so the coupling’s still not loose from the system perspective.
Messages are sent using a messaging system. You may expect that the coupling is loose as you use the messaging system, but an architecture using a messaging system doesn’t always guarantee loose coupling.

Let’s say a message about the withdrawal of a family account is sent when a member’s identity verification is removed. The physical dependency is eliminated by sending the message. However, it doesn’t loosen the coupling.
Because the message expecting the withdrawal from the family account is published, the message on the member system must also be changed when the family account system’s policy changes. If the message’s publisher informs what to do (command), the code on both sides of the message publisher and receiver should be changed when this task to be done changes, so a high degree of coupling exists.
In addition, there’s a logically dependent relationship remains that the member system is aware of the family account’s business, so we can’t consider the coupling loose. You can say that the degree of coupling is not high physically, but high in concept.
The dependent relationship remains even though the message is published because the message published has the purpose of expecting something from the target domain. If a message sent via a messaging system contains a purpose expecting something from the target domain, this is not called an event. It’s no more than an asynchronous request using the messaging system.
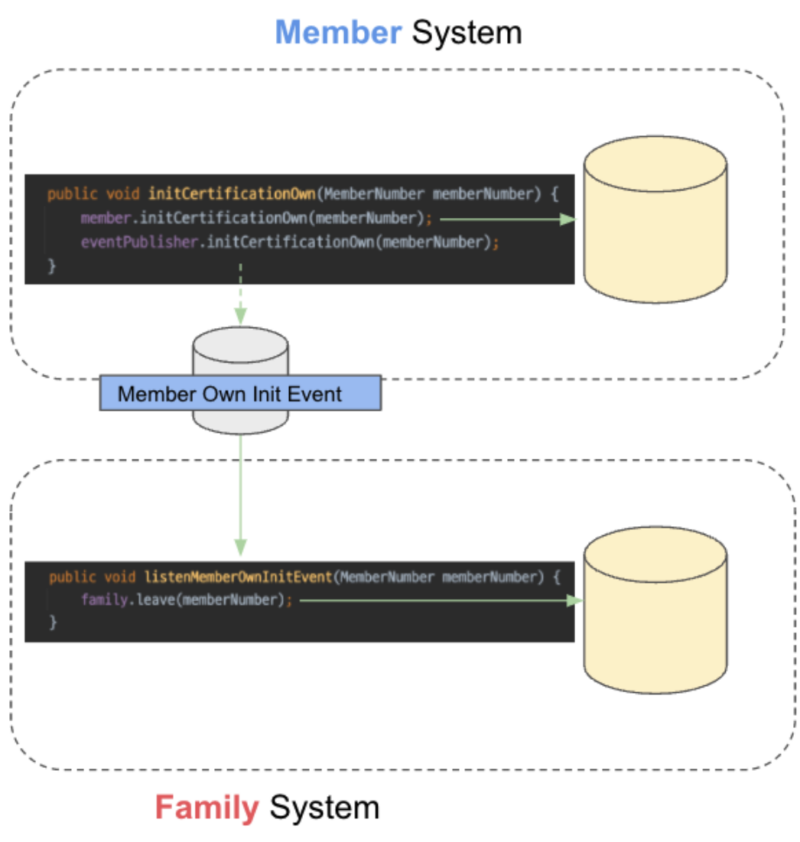
Let’s say an identity verification removal event is sent when a member’s identity verification is removed. The member system doesn’t know the family account system’s policies any longer. The family account system subscribes to identity verification removal events to implement the family account system’s business. The member system is no longer affected by changes in the family account system’s business. Now, the coupling is loose between the two systems.
We’ve looked at the flow of a dependent relationship from a physical system separation to the asynchronous HTTP communication, and to the event method.
We could remove physical dependency using a messaging system, but found out that we get completely different results, depending on the intention of the message.
Events we should publish are not the purpose we want to achieve with the domain event, but the domain event itself.
A domain is a problem area which you want to resolve, and a domain event is a core value or action that may occur in the problem area. Some of you might relate this term domain to Domain-Drive Design (DDD hereafter), so I tell you now it doesn’t have much to do with DDD.
If you have difficulty defining the domain’s core value or action, I recommend you event storming. Event storming is one of DDD’s strategic design tools, but it’s a good tool for identifying problem areas and solving them even when it’s not used for DDD. Event storming for studying domain knowledge
Publication and subscription of events

In the member system, we defined 3 types of events and 3 event subscriber layers to solve various issues. Let’s see why each layer and event has been created and what they resolve.
– Application event & first subscriber layer

Before using a messaging system, we handled Spring Framework‘s Application Event first.
We deal with application first because circumstances, where we have to create a loose coupling through events, don’t just exist in the outside world.
Spring’s application event provides an event bus that can handle distributed-asynchronous tasks and supports transaction control.
The layer of the first subscribers who subscribe to application events may efficiently deal with not-of-interest tasks inside the domain within one application using features provided by Spring’s application event.
One of the domain’s typical not-of-interest tasks that must be resolved within the application is publishing events with a messaging system. Event subscriptions can be expanded or modified freely without impact to the publishing system, so we can create, expand, and modify the connection to the messaging system without affecting the domain.

We can also control transactions through Spring application events. The scope of transaction defined in the domain being able to be controlled externally may be considered an intrusion to the domain, but we can create powerful subscribers by accepting this intrusion.
We’ve established a system policy that any domain activity that causes status change must be delivered via the messaging system. Delivery of events via the messaging system is not the domain’s interest, but it’s an important policy for the system. In this case, we can expand the transaction and make the subscriber’s action be handled within the transaction without any changes to the domain policy.
The member system is using AWS SNS as the messaging system, so an event subscriber has been created who’s in charge of SNS publication for the first subscriber layer.


Note that the events published through these subscribers are internal events.
– Internal event & second subscriber layer

Application events can be used to handle internal events, but the application event processor uses the application’s resources, so it affects the domain’s key task processing performance. In addition, Application Event, as well-implemented as it may be, it can’t have the messaging system’s advantage that minimizes message loss and disaster recovery.
The first subscriber layer handled the not-of-interest tasks that need to be taken care of within the application, the second subscriber layer handles all other not-of-interest tasks in the domain.
Separation of not-of-interest tasks
There may be policies that need to be undertaken with domain activities when they are conducted. These additional policies may be mistaken for the domain’s main action, and it expands a dependent relationship and interferes with cohesion around the domain’s main activity.
Let’s take a look at a login process, as an example of the separation of not-of-interest tasks within a domain.
When a member logs in,
- Change the member’s status to logged-in
- Make the same account log out from other devices where the account is logged in, according to the “limitation of logins of the same account”
- Record which device the member logged in
- Record the log out of other accounts on the same device
the above tasks need to be done.

Looking at the code above, it’s hard to determine which is the domain’s main activity. It’s because additional policies are written in the domain logic together with the main one. We have to increase the domain activity’s cohesion and loosen the coupling to not-of-interest tasks by locating the key feature and separating not-of-interest tasks. You should be able to find a domain’s main activity when looking at the policies. If the policies are vague, you can locate the domain’s main function by separating what needs to be done immediately and what needs to be done later.
The main activity of a login function is to “change the member’s status to the logged-in status.” Other activities are policies additionally attached to the activity of logging in. Separate the additional policies from the domain logic.

You can also see the 3 not-of-interest tasks are not dependent on each other. We can divide one event to multiple subscriptions and process them through the AWS SNS-SQS messaging system.
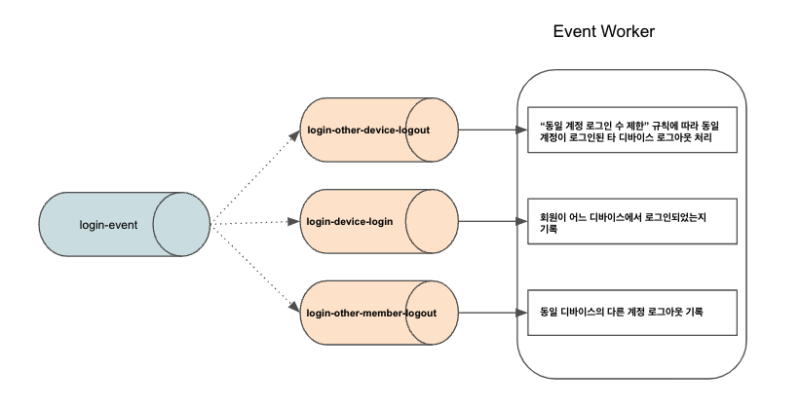

By separating not-of-interest tasks in a domain like this, we can increase the cohesion of the domain activity and loosen coupling with not-of-interest tasks. In addition, not-of-interest tasks separated can be implemented independently to secure strong cohesion and high reusability.
Publication of external events
We’ve separated not-of-interest in the system, but now the publication of external events is needed for separating not-of-interest tasks from the external system for MSA. An action of delivering events to the external system can also be considered as a not-of-interest task that has been in the domain.


Like handling other internal events, the external event gets published by the event subscriber who is in charge of SNS publication for the second subscriber layer.
– External event & third subscriber layer

You can allow internal events to be subscribed from outside, but there’s an advantage of being able to offer an event that is internally open and externally closed by separating internal and external events.
Each subscriber has a different purpose, even if they receive the same event. For this, each subscriber may need more data to recognize the event properly.
Open internal event, closed external event
A subscriber may provide necessary data to the payload and get the efficiency of event handling for internal events. Such payload expansion can be allowed because this event is an internal event. Internal events exist within the system, so you can understand and manage the impact the event’s publication may have on the subscribers. You can internalize internal concepts that don’t need to be open to the public in these events as well. Such expansion is possible, also because internal events exist within the system.
However, external events, to be delivered to an external system, are different from internal events. Internal events have the purpose of increasing domain cohesion and efficiently handling not-of-interest tasks by separating not-of-interest tasks that are in the domain, while external events aim to reduce the coupling between the systems. Published to loosen inter-system couplings, an external event should not care about what the event subscribers do at the place where the event is published, and can’t manage them either. If the place of publishing the event gets interested in the actions of event subscribers, then it forms a logical dependency again.
An external system would probably need more information to process an event. However, if we add the data needed by the external system’s business to the payload, it will form a direct dependent relationship with the external system’s business changes. Event generalization is required so the event can be delivered in a format in order to create an event that doesn’t have any dependency with external systems.
Event generalization
The activities an external system wants to do using an event may be wide in range, but the process of recognizing the event can be generalized easily.
“Which member (identifier) did what (activity) when, that caused what changes (change’s attributes)?“
You can see that any system can recognize the necessary event if there’s an identifier, action, attribute, and event time. By implementing them as a payload, the event’s receiver side may classify necessary events to conduct the actions required by each system.

External systems may carry out actions necessary within the specified event format, so the system that publishes the event may not be affected by changes in external systems.
Tip. Subscribing events that are wanted by subscribers only, using the SNS attributes
Each subscriber may use the event filtering feature based on the “AWS SNS” attributes.
https://docs.aws.amazon.com/sns/latest/dg/sns-message-filtering.html
Each subscriber may define an event format or attribute type required to only receive events needed by the application. With the filtering feature, the wasting of resources that happens by the application classifying events itself can be reduced.
Zero-Payload Method
We chose ZERO-PAYLOAD method to deliver additional data of closed external events.

ZERO-PAYLOAD method is often introduced as the solution to problems associated with events’ order guarantee, but it also has an advantage of removing dependency on external systems from the payload and creating a loose coupling.
External systems can filter generalized events and subscribe to necessary events, and use API for additional information needed to use the latest guaranteed data.

We were able to control events’ transactions through application events, efficiently separate internal not-of-interest tasks through internal events, and publish events that have no dependency on external systems through external events.
This is how event-based architecture is built in the member system.
Building event storage
We were able to separate events’ layers and handle events stably through the messaging system, but problems still existed.
The first problem. Loss of event publication guarantee
It’s possible to stably handle failures and retries through SQS policies in the SNS-SQS-Application section, but HTTP communication is used in the Application-SNS section, so problems may occur in the process of publishing events.

The process of publishing internal events was defined inside the transaction, and the messaging system’s failure may directly lead to the system’s failure. The messaging system’s failure leading to system failure is a huge problem and must be solved.

This problem can be solved by defining the publication of internal events to be after a transaction.

However, it’s handled outside the transaction, so we don’t have a guarantee for event publication anymore. HTTP communication is used in the Application-SNS section, and a failure may occur due to various problems in the network section.
The second problem. Republishing event
Even if subscribers handle events successfully, the handling may go wrong and we should be able to republish events for them at any time.
Here, the shapes of the events the subscribers want are free. They may want a specific event, of a specific period, for a specific member, of a specific type, or a specific attribute to be published. Some messaging systems provide the republication feature, but not all of them. It’s hard for them to accept all these requests as well.
Most data is stored as the final status and it’s difficult to restore it to a status of a specific point in time, and even if you have the history, it’s not easy to restore the event with the data stored without considering events.
To solve these two problems, we decided to build an event storage.
Point of saving event
In order to prevent a messaging system failure to lead to a system failure, we defined the publication of events via a messaging system as a separate transaction. This broke the definition that “publishing event via a messaging system is considered the domain’s main activity,” and it also invalidated the guarantee for event publication.
To restore this definition to the event storage, we redefined “saving an event in the event storage as the domain’s main action.” There is a risk that all domain events must be saved in a storage, and when saving fails, the domain action is also considered failed. Such a definition is needed because data must be guaranteed somewhere.

With definition, we created a subscriber who handles storing in an event storage within the range of transaction.

Storage type
You might think we should choose another database that’s not RDBMS since events are stored in small units and should be processed quickly.
If we use a different type of database from the domain storage, transaction processing must be enabled for both storages. However, it’s extremely hard to implement distributed transactions for heterogeneous databases.

If we choose the same type of storage for event and domain storage, we can trust DBMS for transaction processing, and we can also ensure data consistency through transactions even when a failure occurs on the infrastructure.
Saving databases through the same storage and ensuring stable consistency for publishing events are also referred to as the Transactional outbox Pattern. The key to this pattern is to use local transactions (using the same storage) to save databases and ensure consistency in publishing events. The decision to use event storage was to solve the problem of guarantee for event publication, so this might be considered another way of implementing Transactional outbox Pattern.

Performance risks about reading and writing amount in single storage may be accompanied, but this can be handled sufficiently by expanding, such as scaling up/out, or sharding.
So we chose RDBMS for our event storage, which is the same storage as our domain storage.
Data format
It must be possible to verify that an event has been published in order to ensure the event’s publication.
To check whether an event is published, we needed a flag indicating the publication status, and an identifier for the event itself as well.

It should be possible to republish events by querying a specific member, action, attribute change, or period.
Fortunately, generalization that could be the solution of event query has already been done, when we handle external event publications. Now we know that any system can recognize the necessary event if there’s an “identifier,” “action,” “attribute,” and “event time.”
So let’s define an “identifier,” “action,” “attribute,” and “event time” to get the event query solved.

It should be possible to republish events by querying a specific member, action, attribute change, or period.
Fortunately, generalization that could be the solution of event query has already been done, when we handle external event publications. Now we know that any system can recognize the necessary event if there’s an “identifier,” “action,” “attribute,” and “event time.”
So let’s define an “identifier,” “action,” “attribute,” and “event time” to get the event query solved.


Thus, the storage schema for solving problems has been configured.
Solving problems
Event publishing guarantee
Where we needed a guarantee for event publishing was the process of publishing an internal event. When the first event is recorded, the publishing status was saved as false, and the data was updated by adding a subscriber that records whether the event has been published to the second subscriber layer.
Here, the subscriber that records whether the event has been published can be processed with just the event ID. All events’ super class have been defined so that all events have their own event ID.

The subscriber uses the common payload of events, so all SNS events can be subscribed and processed with a single Queue.


- When a domain event occurs, the
event storing subscriber on the first layerexpands the transaction, so the event is stored in the storage along with the domain action. - The
SNS publishing subscriber on the first layerpublishes an internal event using SNS when the domain’s transaction has been successfully processed, because of theAFTER_COMMIToption. The second layer's event publishing record subscriberreceives internal events and records that the event has been published successfully.
Now, if an internal event has been published successfully via the messaging system, the event’s publishing status will be updated without fail. We organized a batch program so that the system, rather than a human, detects any case of missed event publishing and republishes it automatically. This batch program republishes events that haven’t been published after 5 minutes of the event’s storing to SNS.
- The set limit is 5 minutes because we had configured the retries from
AWS SQSto be continued for up to 5 minutes. - This batch program doesn’t change the events’ statuses directly. It’s because if the event is republished and relayed to the messaging system successfully, it will be subscribed by the subscriber that handles event publishing.
- Events that have not been published successfully are automatically republished by
event publishing detection batch.
Like this, we built an event system where message publishing is guaranteed through an event storage, a publishing handler subscriber, and a batch program.
Republishing event
All events are there in the event storage, so you can republish all and any events through the event storage.

We built a batch program to handle this easily.
We enabled the selection of internal event and external event to publish events with the conditions of period, specific action, specific attribute, specific member, and specific event.

Tip. Sending event to a specific subscriber layer using the SNS attribute
Each subscriber may use the event filtering feature based on the AWS SNS attributes.
https://docs.aws.amazon.com/sns/latest/dg/sns-message-filtering.html
We defined the attribute called “target” for all SNS attributes.
Issue a unique ID for each subscriber, and define unique ID and ALL as the conditions for target.
ALL is a shared attribute for all subscribers that enables them to subscribe to all events.
Normally, it publishes using the ALL type for the target attribute so that all subscribers can use the event. However, if an event needs to be published for a specific subscriber, it publishes by entering the unique ID in the target attribute in the batch system.
With this method, you can create a mechanism to publish events for specific subscribers only.
Integration of record tables
The member system handles personal information, and there are many requirements for data queries.
The member activities must be able to be tracked to resolve issues that came in through the customer center, to track fraudulent users and to cooperate with an investigation agency, etc. Thus, there used to exist dozens of record tables in the member system to fulfill these requests.

All member activities are stored in a consistent way by building of the event storage and the separate record tables have become unnecessary.

Building event-based architecture for the member system is complete with the building of the event storage.
Closing
Member is a domain that exists on most systems. It’s one of the most common domains that exist on any system, but also one of the most central domains as all domains are dependent on the member. It’s also the most critical domain because it intensively deals with personal information.
This event-based architecture was created as the result of considerations for the member domain, located at the very center of MSA, to not be affected by external systems, not to affect external systems, and to safely handle members’ personal information.
We continue to think of the member system as the most stable system in the center of MSA.
Woowa is Delivery Hero’s South Korean subsidiary and operator of Baedal Minjok.
Please note: This article is an English translation of Kwon Yong-geun’s blog post titled “Building an event-based architecture for member systems” published in April 2022 for global affiliates and readers.



