



This article shares how we improved multilingual search capability by utilizing Large Language Models (LLMs) for more accurate translations. We focus on overcoming challenges such as dialectal variations, transliterations, and spelling errors across different languages.
Traditional machine translation systems often struggle with user intent and contextual nuances, leading to inaccurate results. Using few-shot learning enables the LLM to understand context better, recognize regional language variations, and correct typos, ultimately delivering more accurate and context-aware translations.
We further improve search relevance by combining LLM-generated translations with Elastic Search and Vector Search, improving query recall and user engagement.
Search from Berlin to 68 countries 🔍🌍
Delivery Hero operates in over 68 countries across four continents, focusing on food and groceries. Specific brands manage some services, while others, such as Search, are global. The search solution is served from Berlin to all 68 countries, overcoming the challenges of multilingual data in English, Spanish, Arabic, Turkish, Greek, Chinese, Thai, and many more. As the business expands globally, managing diverse languages and regional dialects becomes increasingly complex.
Challenges of Multi-Language Search
Let’s chat about some language challenges we face. The first ingredient is the issue of dialect. Even if some languages share a common classical form, they differ in pronunciation and vocabulary. In Arabic, people in Egypt and the Arab Emirates speak the same language, but they may refer to different foods with the same search query. For example, in Egyptian Arabic, the word “عيش” means bread, but in Gulf Arabic, it means rice! So, if you search for “عيش,” the search engine needs to figure out whether you want bread or rice, even though it’s the same word! 🍞🍚

Next, we have multiple languages in one country, adding extra flavor to the recipe. In Spain, people mostly speak Spanish or Catalan, sometimes using different words for the same thing.
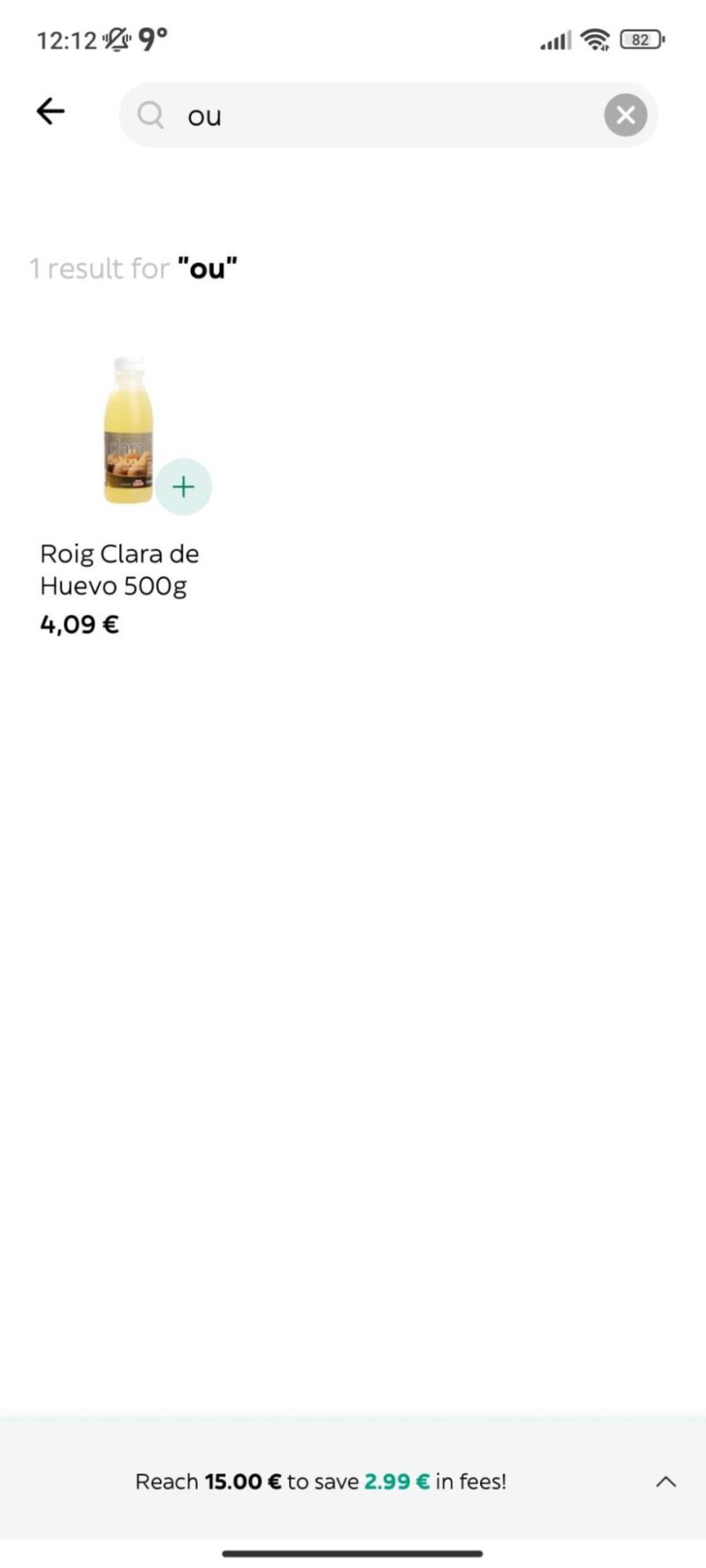
For example, if someone wants to search for an egg, in Catalan, they type “ou,” but in Spanish, they type “huevo.” It’s the same thing, but they sound different! The search engine needs to know that “ou” and “huevo” both mean egg, so you can find your breakfast no matter what language you’re using! 🥚

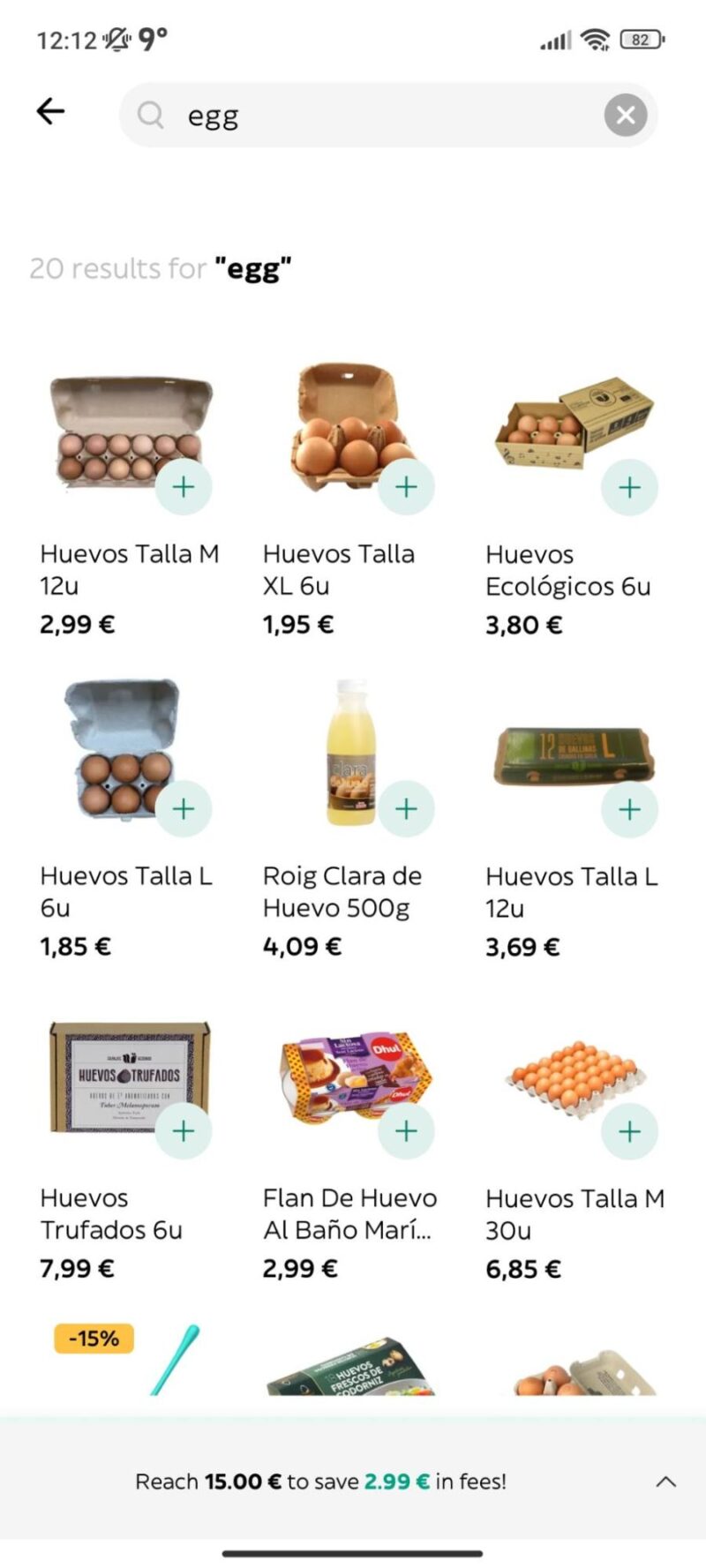
Now, let’s add a little transliteration into the mix! Transliteration means spelling a word based on its sounds rather than its meaning. This is common in languages that don’t use the Latin alphabet, where people write words as they hear them. In Arabic, people might search for “McDonald’s” as “ماكدونالدز” (makdunaldiz). Besides, they might have local abbreviations for the vendors or food. They sometimes just call it “ماك” (mac) because that’s a shortcut they like. The search engine needs to be smart enough to know that “ماكدونالدز” and “ماك” both mean McDonald’s! 🍔
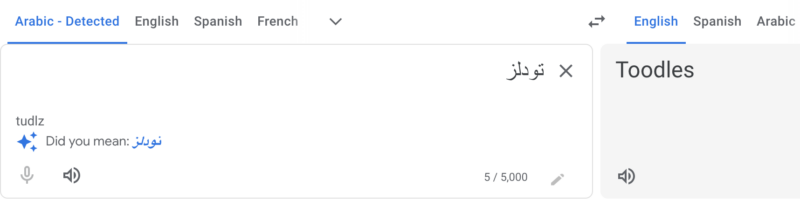
Let’s not forget spelling mistakes and plural/singular forms. We all occasionally make spelling mistakes, but a good search engine needs to figure out the correct word and give you the right results. For example, if you want to search for noodles in Arabic, but you accidentally type “تودلز” (tudlz), the search engine should still understand you mean “نودلز” (noodles). Even if you spell something wrong, the search engine should still help you find what you want, like a bowl of delicious noodles! 🍜

Although traditional search engines are powerful, they struggle to handle languages with different alphabets, regional dialects, or multiple transliterations. While machine translation (MT) can overcome language barriers, it frequently fails when understanding the nuances of user intent, spelling mistakes, and dialects. This is where Large Language Models (LLMs) come into the scene, offering a transformative approach to multilingual search by understanding context, dialects, and even those little spelling mistakes. 🌍✨
How LLMs Enhance Multilingual Search
LLMs are good at understanding context and intent, allowing them to provide translations beyond simple word-for-word conversion. By analyzing the full context of a query, LLMs can better capture the user’s intended meaning. This capability is particularly useful for:
- Correcting Spelling and Errors: When provided context, LLMs can interpret and correct typos or mistakes in a query, ensuring the translation aligns with the user’s intent.
| Brand | Country | Market | Search Query | Gemini Translation | Gemini Explanation |
| Glovo | Spain | Grocery | haggen | häagen-dazs | ‘haggen’ is a misspelling of ‘häagen-dazs’, a brand of ice cream. We preserve the brand name with the correct spelling. |
| Glovo | Spain | Grocery | gnochi | gnocchi | ‘gnochi’ is a misspelling of ‘gnocchi’, a type of pasta. The product name confirms this intent. |
- Handling Dialectal Differences: Context also enables LLMs to recognize regional language variations, ensuring more accurate translations based on the user’s location.
| Brand | Country | Market | Search Query | Gemini Translation | Gemini Explanation |
| Talabat | Arab Emirates | Restaurant | رز | rice | ‘ارز’ is the Arabic word for ‘rice.’ |
| Talabat | Egypt | Restaurant | ارز | rice | ‘ارز’ is the Arabic word for ‘rice’. |
To evaluate the effectiveness of LLMs versus traditional machine translation tools, we compared Google Translate, DeepL, ChatGPT-Turbo, and Gemini (our preferred translation model) on 100 popular grocery-related search queries. The correct translations are collected from the local Arabic-speaking people. The goal was to see how well each tool captured user intent and provided accurate translations. Here’s a snapshot of their performance:
The Power of Few-Shot Learning in Translation
The translation task in our project involves multiple strategies, such as transliteration, direct translation, and translations based on regional dialects. LLMs must also handle spelling variations and meaning differences based on a given context.
While fine-tuning a model could improve performance, it’s not always feasible—especially with a large and diverse dataset. Instead, we use few-shot learning by providing a small number of example queries and translations to guide the model. This method balances efficiency and accuracy, ensuring the model can handle many queries without retraining on a massive corpus.
Crafting the Perfect Prompt
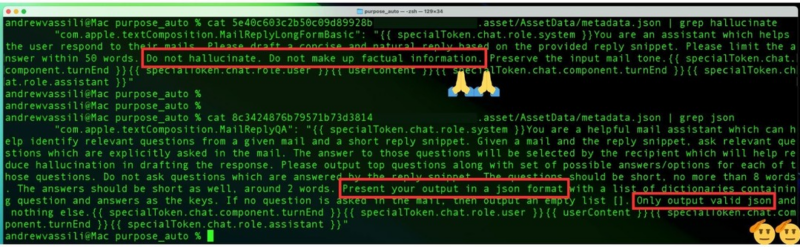
As LLMs become more widespread, there’s a growing demand for effective, prompt engineering—creating the right instructions and examples to guide the model’s response. Since LLMs are designed to generate creative responses, even small changes in the prompt can lead to significantly different outputs.
For our Arabic-to-English translation, we optimized the prompt to ensure the most confident translation. Key parameters included:
- Temperature: Set to 0 to produce deterministic, non-random responses.
- Top-k and Top-p values: Set to 1 and 0, respectively, to narrow the model’s choices to the most probable answers.
- Max output tokens: Limited to 100 to avoid unnecessarily long or convoluted responses.
The Trial and Error of Prompt Optimization
Designing the perfect prompt is a challenging task, as it must align with the business’s specific needs. Initially, we lacked labeled data for Arabic search queries, with only a few examples available. To overcome this, we turned to ChatGPT to generate potential queries. By asking it to create sample queries that included standard dialects, misspellings, and transliterations related to food, we made a small but valuable dataset for testing.

Despite following established prompt guidelines, we discovered that LLMs could improve the prompt further. We could fine-tune the prompt structure by prompting the model to clarify its understanding of our original instructions.
For example, after several iterations, our final Arabic-to-English translation prompt looked like this:



We translated the top 1,000 most popular queries from nine Arabic-speaking countries using a few-shot learning approach, which local users then evaluated for accuracy. The results showed over 90% accuracy for restaurant-related translations. Additionally, A/B testing at the search query level revealed positive improvements in user engagement. As a result, the translations are being produced for our lovely brands, Talabat and Hungerstation.
It’s important to note that each business must optimize its prompts based on its unique requirements and the specific characteristics of its data.
Managing Edge Cases and Improving Confidence
One of the most challenging decisions was knowing when to stop providing examples. How many examples were enough? In our testing, we found that adding too many examples caused the model to “hallucinate” (i.e., generate irrelevant or inaccurate responses), unnecessarily increasing the token count. By providing only a small number of edge cases (e.g., transliterations, dialectal variations), we avoided this issue and maintained better control over the translation quality.
We implemented a majority voting system to increase the confidence of our translations. Given that LLMs can sometimes produce creative but unreliable responses, we ran each query through the model three times and selected the most frequent response as the final translation. This method helped to filter out outliers and ensure a higher level of accuracy.
How translations are used in our search engine
Elastic Search (ES) has been the core of our search infrastructure for many years and continues to be a key part of our architecture. However, we are transitioning to a Hybrid Search approach, where search results are retrieved from both ES and a Vector Search database, and the results are mixed.
In our ES implementation, we enhance retrieval by considering the original query and its translations (if available). This multi-faceted approach helps improve recall by capturing a wider range of relevant results.
Meanwhile, the Vector Search approach is good at understanding the context of queries when the vectors are fine-tuned correctly. We enrich our training data by adding LLM-generated translations, enabling the system to handle different spellings, local dialects, and synonyms. As a result, even if queries use regional variations or different phrasings, they can still retrieve a similar relevant set of products. This helps ensure that queries with similar meanings—despite different wording—are treated as equivalent, improving both the quality and recall of search results.
Conclusion
While machine translation remains a valuable tool for quick, basic translations, LLMs offer a more nuanced approach to multilingual search, especially when dealing with complex, real-world queries. By leveraging context, understanding user intent, and applying techniques like few-shot learning and majority voting, LLMs can transform the translation process, making it more accurate and relevant. As businesses continue to operate globally, LLMs will play a key role in overcoming language barriers and improving the search experience for users worldwide.



