



The global Swimlanes API, a business-critical system deployed in multiple regions, handles tens of thousands of requests per minute. It provides our customers with programmed and personalized lanes of restaurants to order from.
In this post, I’ll walk you through the steps we took to rebuild the API, avoiding a Big Bang migration by following the Chicken Little approach: incrementally moving features from the old API into the new codebase and deploying them to production.
We introduced these changes while respecting our SLOs, without introducing downtime, and while keeping deployment risks low.
Swimlanes API
Delivery Hero operates several brands globally, which use the Swimlanes API to enhance the discovery experience of our customers when searching for restaurants.
The API is responsible for presenting restaurants available to a customer in a given area, grouping them into swimlanes based on predefined business rules. Each swimlane will be displayed as a horizontal scroll.
There are multiple types of swimlanes, each requiring its own set of rules to be built. For example, there are some that require personalization, such as Recommended Restaurants, and others that require custom filtering, like Free Delivery.
Why Migrate?
Version 1.0 of this API was originally conceived a few years ago as a monolithic application responsible for a wide range of business functions. The name of the API was Core, hinting it did lots of foundational work. Serving Swimlanes was only one of its responsibilities.
As time passed and the company grew, new teams spawned from the core team, each specializing in a different area of the system. The Swimlanes team kept using the Core API, but the codebase was no longer tuned for its specific purpose, making maintainability hard to achieve.
As well as that, the Core API was built originally in Scala, and this programming language was no longer a favorite among the engineers in the company, who were moving away to other languages such as Java. This meant we were not looking for Scala engineers during our hiring process, making it harder to find engineers ready to work on this API.
As a result, the API was slow to scale, and new features were hard to incorporate. Since Swimlanes was the last piece standing in the original Core API, it was decided the Swimlanes API needed an upgrade.
Tech Stack
The original API is load-tested weekly with at least 200k requests per minute. For each request it receives, it needs to generate multiple concurrent web service calls to downstream services and mash up their responses, making it an I/O-intensive API.
Our goal was to build a scalable non-blocking system that can serve thousands of requests per minute from around the world.
Swimlanes API deployments
We decided to build Swimlanes as a Reactive RESTful API, using Spring WebFlux as the underlying framework.
The application was to be deployed in clusters from different regions using Google Kubernetes Engine.
Approach
To avoid a Big Bang migration, we decided to start delivering functionality quickly and iteratively. Our goal was to migrate pieces of functionality from the old application into the new one and run both applications in parallel.
Taking advantage of the fact that our different Swimlane types are relatively independent of each other, we decided to migrate them one by one, in iterations.
The following were the steps we took:
- Create the new Swimlanes V2.0 API as a Gateway that redirects all calls to V1.0
- Release Swimlanes V2.0 to Production, and send all traffic to it.
- Migrate swimlanes in iterations:
- Build one swimlane type in V2.0
- Test swimlane with shadow traffic
- Test swimlane with A/B tests
- Fully serve new swimlane from V2.0
- Delete swimlane from V1.0
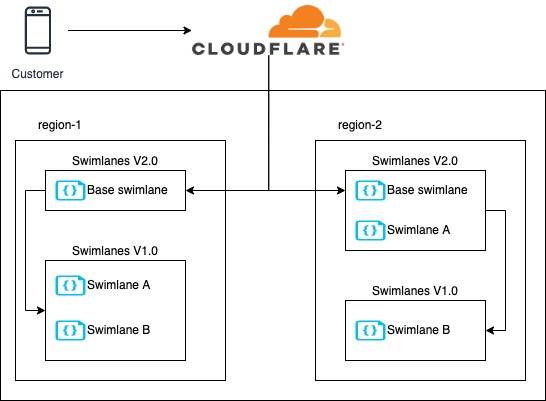
Since our application is highly available, it has deployments in two different regions per continent. This allowed us to gradually test changes in one region first, without impacting all customers.
A/B Testing Swimlane A
Start with a simple Gateway
The first iteration of v2.0 was an empty API that received requests but didn’t build any swimlanes by itself. Instead, it redirected all calls to the original API to build them all.
We then applied a divide and conquer strategy, treating each different type of swimlane as a separate component. We migrated swimlanes one by one into v2.0, but still relied on v1.0 to build the swimlanes we had not migrated yet. As we made progress, the number of swimlanes that we needed to build in v1.0 was steadily decreasing.
This approach allowed us to start working and releasing new swimlanes, one at a time in v2.0, while at the same time removing swimlanes, one at a time from v1.0, avoiding a Big Bang release. The price to pay was adding ~25ms in response time due to the overhead of the extra call to v1.0. This was acceptable since it didn’t reach our SLO limits.
The call to v1.0 was both asynchronous and concurrent, so both v1.0 and v2.0 worked in parallel to build the swimlanes needed for each request.
Shadowing
During the shadowing phase of each swimlane built, we continued to build the swimlane with Swimlanes v1.0, but we duplicated 5% of the requests and asynchronously built them with the v2.0 version. This allowed us to use a sample of production traffic to test the new swimlane, without affecting any customers.
We had dashboards in place to compare shadowed traffic performance in v1.0 vs v2.0, which helped us validate that everything looked good before serving real traffic.
A/B Testing
Once we felt comfortable with the results of the shadowing phase, we A/B tested the new swimlane, splitting traffic between v1.0 and v2.0. In this phase we tracked our conversion rate to validate the impact of our changes, and we created new Datadog monitors to validate latency and errors.
We considered our tests successful if the new swimlane was showing the same or lower error rate/ response time, and the same or higher conversion rate.
Once A/B tests were successful, we rolled out the v2.0 swimlane and moved on to the next.
With this approach, we were able to achieve our objective of migrating all of our swimlanes with zero downtime and no performance degradation. As a welcomed side effect, we managed to see in real time that the new API was performing ~22% faster than the old version while using 80% fewer pods.
Conclusion
Making the decision to rewrite an existing API requires a lot of consideration, and the actual migration process is challenging, at the very least.
These considerations allowed us to have a successful project:
- Starting with a Gateway allowed us to be in production quickly, which was the groundwork to start delivering features iteratively.
- Merging partial responses from v1.0 and v2.0 to provide a full response, allowed us to gradually release new functionality.
- Shadowing calls from production to our new API helped us monitor the performance of our application before release.
- A/B testing between v1.0 and v2.0 allowed us to compare results and make sure we were releasing a quality product.
Some drawbacks we faced with our strategy:
- Merging responses from v1.0 and v2.0 added latency to our calls, making it harder to measure the actual response times of the new API during the transition period.
- While performing the migration we had to support the infrastructure of two live systems doing similar things.
In the end, the way the project was executed allowed us to have a smooth progressive experience without any major roadblocks or concerns.
Interested in working with us? Check out some of our latest openings, or join our Talent Community to stay up to date with what’s going on at Delivery Hero and receive customized job alerts!



