



Explore the second story of how the BADA (Baemin Advanced Data Analytics) team at Woowa Brothers developed an LLM-based agentic product to enhance data literacy.
In Part 1. Utilization of RAG and Text-to-SQL, we covered the development background, purpose, and core features of the AI data analyst QueryAnswerBird(QAB), which helps improve our employees’ data literacy. We also detailed the implementation methods for technologies such as RAG, LLMOps, and Text-to-SQL. In Part 2, we will talk about QAB’s Data Discovery feature, which goes beyond Text-to-SQL to explore and understand various internal data using LLMs to derive meaningful insights.
1. WHY did we expand into Data Discovery?
1.1 User beta testing
We conducted two rounds of beta testing to verify the usefulness of QAB’s features and identify areas for improvement based on user feedback. This process provided valuable development insights from various user questions.
In the first beta test, we tested the initial version of the Text-to-SQL feature with data analysts and engineers. We received feedback on text-to-SQL-based query generation capabilities, such as table selection accuracy and business logic application, and identified the need to improve Trino query functions and response times. We also discovered a demand for not only text-to-SQL-based query generation but also for query explanation.
The second beta test was conducted with product managers (PMs). This test verified the practical usability of QAB and assessed its feasibility in non-data-related roles. The collected questions included not only text-to-SQL-based query generation but also various data discovery inquiries including those about query interpretation, table explanations, exploration of specific tables and columns containing specific information, and the utilization of log data. This allowed us to identify features that could be more useful for a broader range of users.

1.2 Addition of Data Discovery Feature
Based on insights gained from user beta testing, QAB has added a Data Discovery feature capable of understanding and responding to a wide range of user questions. This feature utilizes a vector store to manage data from the company’s Data Discovery Platform, including the Data Catalog, which contains detailed information on all internal tables and columns and the Log Checker which manages user behaviour and event data from apps and websites at the log level, in a vector store. This allows QAB to understand user questions, acquire relevant information, and provide answers. When more detailed information is needed, users can access the Data Catalog or Log Checker to maximize the synergy of data utilization.
Specifically, the Data Discovery feature includes not only text-to-SQL-based query generation but also various information acquisition functions that help improve employees’ data literacy by providing explanations of queries and tables as well as guidance on utilizing log data. Below are the features currently available and detailed descriptions of each.
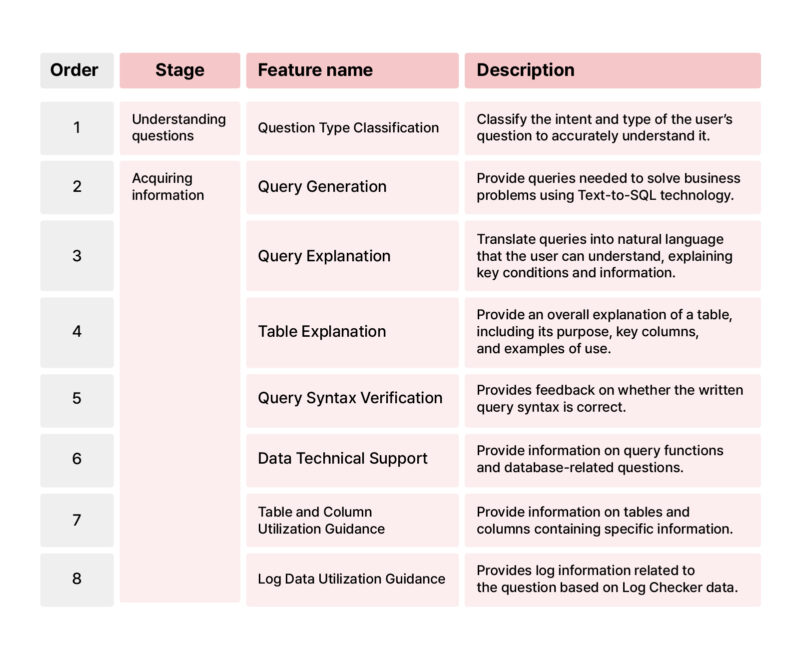
1.3 Structure of Data Discovery Feature
The Data Discovery feature is implemented in a layered structure based on question understanding and information acquisition. This approach minimizes the hallucination issues of LLMs by accurately understanding a wide range of user questions and ensuring the scalability of the Data Discovery feature.

Let’s take a closer look at how we implemented the first step, “Understanding questions,” and the second step, “Acquiring information,” in our Data Discovery structure.
2. HOW was the question understanding stage implemented?
It was challenging to handle all types of questions within a single chain because a wide variety of questions were asked in addition to those about query generation. Moreover, the level of questions varied greatly due to differences in users’ understanding and ability to utilize data. For example, some users might ask, “Calculate the percentage of STOD orders from yesterday’s Order Master table, excluding test restaurants, rounded to the second decimal place,” while others might not even know how to start their question.
Therefore, it was necessary to enhance the quality of questions and connect them to appropriate chains to improve the quality of answers, regardless of the users’ data utilization capabilities. To achieve this, we implemented a Router Supervisor chain that accurately understands user intent and delivers appropriate answers. The Router Supervisor chain was inspired by the Agent Supervisor concept from LangGraph. Let’s take a closer look.
2.1 Ways to improve user questions
(1) Enhance question interpretation ability
A stage was needed to evaluate how closely the received question is related to data and how many specific clues it contains for problem-solving. This additional stage was added because even if question types are classified through LLM, errors can still occur, requiring a second evaluation of the question’s quality. We established criteria for question evaluation and calculated a total score by summing the points for each evaluation item. We assigned consistent scores to determine if the criteria were sufficiently met using prompt engineering techniques. During the scoring process, we used a vector store, similar to the Text-to-SQL process, to combine internal terminology with questions, converting abstract or specialized questions into more easily understood ones. Questions that meet a certain score threshold and pass the classification model proceed to the next stage—information acquisition. Questions that do not meet these criteria are automatically prompted with a message to ask more specific questions, with appropriate examples provided for reference.
(2) Improve question generation ability
In addition to enhancing question interpretation ability, we considered ways to improve users’ question generation skills. We provided user guides to help them ask appropriate questions for specific problem situations. However, users frequently asked questions without properly reading the guide, leading to cases where they did not receive the desired answers. To address this, we developed an intuitive user guide, a tutorial-like usage guide screen, which is provided to users upon their registration of the QAB on Slack. This guide helps users understand which questions they can ask and what kind of answers they can expect by providing examples of the currently available features, along with representative questions and sample answers for each feature.
The response methods by conversation type are as follows.
2.2 Response methods by conversation type
(1) Single-turn conversations
A Single-Turn conversation consists of a single question and response. While it is simple to implement and offers fast response times, it has the drawback of not maintaining context. In the question understanding stage, response speed is crucial, so Single-Turn interactions are primarily used. According to beta test results, it was found that more than 10% of questions were unrelated to the data. Connecting such questions to Text-to-SQL may result in incorrect answers. Therefore, users’ questions are initially classified automatically based on whether they are data or business-related. Questions unrelated to these, such as weather inquiries or greetings, are classified as general conversations and answered appropriately without additional processing. Traditionally, sentence classification was performed using machine learning-based models, but recently, automatic classification has become possible with LLM-based prompt engineering. This has made the implementation easier and improved classification performance.
If a question is categorized as data-related or business-related, it is further classified based on the type of information it requires. For instance, the question is categorized based on whether it requires an explanatory answer or a verification response. In cases where two questions are asked, the answer that is most suitable for the feature’s priority and solving the problem is provided first. Through this two-step classification process, the most appropriate answer is given to the user’s question.
(2) Guided Single-Turn conversations
The Guided Single-Turn conversation type consists of a single question and response but directs the conversation in a specific way. When the question is vague, QAB provides a guide for question formulation, encouraging the user to be more specific. While this isn’t a Multi-Turn conversation, it provides users with an experience similar to it.
(3) Multi-Turn conversations
The Multi-Turn conversations involve a series of questions and responses, maintaining context throughout. This allows for extended conversations and continuous interaction. However, when connected with various functions, there is a risk of generating hallucination responses, so thorough testing is necessary before implementation. Currently, QAB is developing a stable Multi-Turn feature to ensure reliable service.
So far, we have discussed the first stage of Data Discovery—understanding questions. By employing the previously explained strategies, we were able to enhance the completeness of user questions and effectively respond to a wide range of questions. This, in turn, improved user satisfaction and reliability.
Next, we will explain the information acquisition stage, which provides specific answers to user questions categorized during the question understanding stage. The information acquisition stage can be divided into four composite functions—Query and Table Explanation, Query Syntax Verification and Data Technical Support, Table and Column Utilization Guidance, and Log Data Utilization Guidance, or seven detailed functions.
3. HOW was the information acquisition stage implemented?
3.1 Query and Table Explanation Function
(1) Background
Data analysis and its associated queries play a crucial role in the process of developing and improving services. As a result, a wide range of our employees, from those well-versed in data to those less familiar with it, utilize queries in various areas. However, as Baemin services diversify and become more sophisticated, complex queries – which can be difficult to grasp at a glance- are being generated. As a result, employees who are unfamiliar with queries or the tables they utilise often spend a significant amount of time trying to comprehend these queries. Additionally, when there is a change in the service manager, the person taking over frequently faces challenges in fully understanding the queries that were previously used.
(2) Provided Information
The Query and Table Explanation function was introduced to address the challenges mentioned above. When a user enters a query, the system provides information about key business conditions used in the query, essential columns, the data extracted, and how to effectively utilize it. If the user inputs a table name, the system delivers details about the table’s key columns, column descriptions, and examples of how the table can be utilized. At the end of the response, a link to the Data Catalog information of the table mentioned in the user’s question is provided, allowing them to explore more detailed information.

(3) How the feature is implemented
The implementation of the Query Explanation function begins by extracting table names from the user’s question. The system utilizes a Python library called SQLGlot, along with regular expressions, to anaylze the query to extract the table names. It then retrieves information about these tables from a Data Definition Language (DDL) vector store. If the user’s input includes a table that doesn’t exist in the DDL vector store—such as a user-created table or a table that cannot be shared due to privacy concerns—the response includes a disclaimer, informing the user that the explanation may be inaccurate due to missing or restricted information.
After extracting the DDL of the table referenced in the user question, DDL reduction logic is applied to extract only the information for specific columns. There are two reasons for reducing the DDL. The first reason is that as the length of the prompt input into the LLM increases, the likelihood of hallucination also increases. The second is that in cases where some DDLs have a large number of columns, inputting the entire content into the prompt can result in an error due to the token limit of the LLM. The reduced DDL, generated by applying logic that extracts only the column names used in the query along with essential columns like table keys and partition details, is then input into the prompt. This prompt utilizes the Plan and Solve Prompting method, developed to overcome the limitations of the existing chain-of-thought (CoT) methodology, to guide the interpretation of queries and tables.
3.2 Query Syntax Verification and Data Technical Support Function
(1) Provided Information
The Query Syntax Verification function checks the accuracy of the syntax in the user’s query and, if necessary, suggests improvements for column names, condition values, and execution optimization. This feature is particularly useful when errors occur in long and complex queries or when the user is unfamiliar with query writing and is unsure where the mistake lies.
The Data Technical Support function not only provides assistance with query functions such as “a function to get yesterday’s date,” but also offers expertise related to data science or databases.
(2) How the feature is implemented
The Query Syntax Verification function consists of two detailed chains. The first step is the column name correction chain, which extracts the column and table names used in the query statement, and checks and corrects the column names for errors based on the DDL of the extracted table. After the query is corrected, the DDL is shortened based on the adjusted query.
The second step is the query syntax verification and optimization chain. Based on the corrected query and the shortened DDL received from the previous step, this chain checks for errors in the syntax and column values and suggests optimization strategies. By dividing the process into these two detailed chains, the LLM is assigned more specific roles at each stage, reducing the amount of information required at each stage, which lowers the possibility of hallucinations and further enhances performance.
If there is no query in the user’s question, the information is conveyed through the Data Technical Support function chain to respond.
(3) Limitations
As the name suggests, the Query Syntax Verification function does not propose modifications to the business logic used in the query. This limitation arises because the meta-information regarding the business significance of query conditions is currently built using few-shot SQL example data. Consequently, it is difficult to retrieve and provide detailed information about business logic from the vector store and deliver satisfactory answers.
In addition, in most questions, the user does not specify which detailed logic they wish to modify, making it difficult for the LLM to provide accurate answers. To address this issue and enhance the functionality, we plan to store meta-information in the vector store regarding which columns and condition values should be used for specific business logic. Furthermore, we will add a user guide to encourage more specific questions.
3.3 Table and Column Utilization Guidance Function
(1) Provided Information
The Table and Column Utilization Guidance function assists users in retrieving and using the necessary data more easily by providing table names and column information that contain specific information. For example, if a user asks, “Show me the table that contains information about the Baemin Club membership subscription,” the system responds with the relevant table name, key columns, and examples of how to use the information. Additionally, a link to the Data Catalog is provided, allowing users to access more detailed information. This feature differentiates itself from traditional search functions by delivering a summarized form of comprehensive table information as search results.
(2) How the feature is implemented
To implement the Table and Column Utilization Guidance function, we enhanced the table metadata by utilizing an LLM. As mentioned in the Data Augmentation section for Text-to-SQL implementation in Part 1, the enhanced metadata includes information about the table’s purpose, characteristics, and main keywords, which has proven useful for searching for relevant tables based on user questions. However, during the process of generating metadata for numerous tables using the LLM, hallucination issues occurred, resulting in incorrect information being entered for some tables. We plan to address this issue by further refining the metadata generation prompts and introducing correction logic.
Next, to better understand users’ questions, we implemented a question refinement chain that utilizes a business term dictionary and topic modeling. The business term dictionary allows the LLM to expand user questions based on the service structure and terminology. We also performed topic modeling based on the words that make up the DDL and entered the selected topics and keywords into the question refinement prompts. This approach enables the LLM to identify the keywords most relevant to the user’s question, facilitating table searches using a richer set of keywords.
Lastly, to find the table most closely related to the refined user question, we implemented a hybrid retrieval chain that combines table metadata and DDL-based retrievers with the LLM. This hybrid chain goes through three stages of searching to narrow down from numerous tables to one or two and then provides the user with detailed information about the selected tables.
Next, we will take a look at the Log Data Utilization Guidance feature that explores log data, which is not in a structured format like tables.
3.4 Log Data Utilization Guidance Function
(1) Provided information
The Log Data Utilization Guidance function analyzes user questions to effectively search and utilize the vast log data available in the Log Checker. For example, if a user asks, “Show me the logs related to the Shop Detail page,” QAB extracts specific log terms, such as “ShopDet,” which refers to the shop detail page, to locate the relevant logs and provide guidance on the log structure and meaning, enabling the user to retrieve the desired data.
This function assists employees unfamiliar with log data, those needing to find logs in unfamiliar domains, and those who develop new logs, allowing them to quickly locate and understand the necessary log information.
(2) Pre-processing of data
The Log Data Utilization Guidance function, unlike the other functions mentioned earlier, does not use DDL information from tables but instead utilizes data from the Log Checker. Below is an example of the Log Checker data. Screen Name, Group, Event, and Type refer to the page where the log occurs, the sub-area within the page where the log occurs, the event information triggered by the log, and the log type, respectively.

The table’s DDL information includes both column names and descriptions of the columns. In contrast, while the Log Checker contains a log name and a log description, it does not provide detailed descriptions like those in column comments of DDL. To implement the Log Data Utilisation Guidance function, a new approach was needed. Instead of using the log name as is, we decided to create log descriptions based on the unique combination values of Screen Name, Group, Event, and Type from the Log Checker. However, before creating log descriptions, we needed to address several issues.
The first issue was translating English terms in the Log Checker into Korean. To understand user questions, it is essential to have Korean descriptions for each log. While it would be ideal to use the existing Korean information in the Log Checker, such as log names and log descriptions, the log name lacks sufficient information to fully describe a log, and the log description contains operational explanations that cannot be used as is. To address this issue, we separated the log names into detailed words and created the Log Terminology Dictionary by translating each word.
The second issue was defining terms that are specific to Woowa Brothers. Generally, the Korean word 가게 can be translated as shop, store, and various other terms. However, in Woowa Brothers, 가게 specifically refers to “Shop,” while “Store” means “Baemin Store.” To address terms that cannot convey the correct meaning through translation alone, we added a “Log Terminology Correction Dictionary.”
Lastly, we addressed the issue of abbreviated terms. We needed a way to recognize that an abbreviation like “ShopDet” corresponds to “Shop Detail.” To achieve this, we linked words from the Log Terminology Dictionary to the unique combination values based on similarity. This way, “Shop Detail” is connected to the most similar term, “ShopDet.”
After addressing the three issues mentioned above, we developed new log descriptions. The generated log descriptions are used as log mapping data for user questions. As shown in Figure 5, the newly defined log descriptions are registered, and newly registered logs will undergo the same process for weekly updates.
(3) How the feature is implemented
The Log Data Utilization Guidance feature consists of two main chains. The core of this function is the replacement of existing complex search algorithms with an LLM, allowing for more flexible and straightforward implementation.
The first chain is the log term chain. The log term chain connects user questions with specialized terminology from the log system. First, it calculates the similarity between the user’s question and the terms in the pre-built Log Terminology Dictionary to select highly similar log terms. Then, using the LLM, it selects the final log terms that are most relevant to the user’s question from the selected terms. In this process, the LLM provides results that are contextually understood without requiring complex logic.
The second chain is the log retrieval chain. The log retrieval chain is responsible for filtering and retrieving only the logs that the user wants from the log information stored in the vector store. Based on the selected terms from the log term chain, it searches for related logs in the vector store. The LLM is then used to select the logs that are most relevant to the user’s question from the retrieved logs. To reduce hallucinations, the LLM was instructed to output only the unique key values that can differentiate the logs. Finally, the unique keys output by the LLM is used to retrieve and provide the final logs from the vector store. This method ensures that the selected final log information is provided accurately and without omissions.

This search method utilizing LLMs is more flexible and easier to implement compared to traditional algorithm-based searches. Instead of developing complex search logic, we can leverage the natural language understanding capabilities of LLMs to identify user intent and find relevant logs. The implemented Log Data Utilization Guidance function provides responses to users in a standardized output format, as shown in Figure 6.
4. What will we do with QueryAnswerBird in the future?
So far, we have explored the Text-to-SQL-based query generation function and various data exploration functions. The core characteristic of QAB is its ability to understand user questions and dynamically personalize the required data and prompts in real-time based on the type of question. Moving forward, we plan to continue enhancing these capabilities by introducing new features and technologies.
Specifically, we are planning to develop a “Knowledge Generation” stage in the future. Knowledge generation refers to the process of exploring and visualizing data, then proposing actionable business strategies and planning based on the analyzed information. To implement this, performance improvements in the information acquisition stage and integration between various functions are essential. Therefore, we are considering improving Text-to-SQL performance and introducing an AI agent that combines multiple functionalities rather than relying solely on single functionalities. AI agents are autonomous intelligent systems capable of performing specific tasks without human intervention.
Additionally, we plan to develop various Data Discovery features. To better utilize the in-house BI Portal service, we will suggest dashboards linked to questions that help solve specific problems.
Once these features are developed, they will establish a new foundation for enhancing employee productivity. We anticipate that QAB will be utilized in five stages, from stage 1 to stage 5.
- Stage 1: QAB supports employee tasks by understanding and extracting data, and providing reference materials. At this stage, the employee’s expertise is crucial.
- Stage 2: QAB is delegated some of the employee’s tasks, performing data generation and verification, ensuring that the generated data is reliable.
- Stage 3: Employees and QAB collaborate. They jointly explore and analyze data, and QAB generates information to assist in decision-making.
- Stage 4: QAB proposes data-driven decisions, offering actionable insights directly for decision-making.
- Stage 5: QAB autonomously makes optimal decisions, automating data-driven decision-making to achieve the best possible outcomes.

5. Concluding Part 2 on QueryAnswerBird
QAB, the AI data analyst, is set to continuously evolve, enabling smarter and faster decision-making. Furthermore, we are planning to establish a dedicated team to not only focus on data analysis but also understand a variety of tasks within the organization. This team will open up new areas where we can share and expand our knowledge by answering various questions. We expect QAB to become a unique service of Woowa Brothers through these developments, significantly boosting internal productivity. We appreciate your ongoing support and stay tuned for the future growth of the QAB service at Woowa Brothers.
Please note: This article is an English translation of the BADA(Baemin Advanced Data Analytics) team’s blog post titled “Introducing the AI Data Analyst “QueryAnswerBird” – Part 2. Data Discovery” published in August 2024.
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.











