



How fast and accurately do the top three gradient-boosting algorithm implementations in ML perform on prediction tasks? In this study, we conducted a head-to-head analysis of CatBoost, LightGBM, and XGBoost, utilising an openly accessible WEB10K dataset and uncovered fascinating insights.
As LightGBM, XGBoost and CatBoost utilize different ways of building decision trees, it is not a secret that they differ a lot in performance. Most of the existing literature on this topic focuses purely on training time, but inference latency matters much more for production workloads. In this research, we found out that CatBoost can be much faster in some cases, but you have to make sacrifices with training time.
Typical search [re]ranking
At Delivery Hero, we use quite a traditional approach to build our search. For example, when you type “pizza”, the search request is sent to an ElasticSearch instance to retrieve all items matching the keyword from the query, and then a list of top-N candidates is reranked using a more advanced ML ranking algorithm.
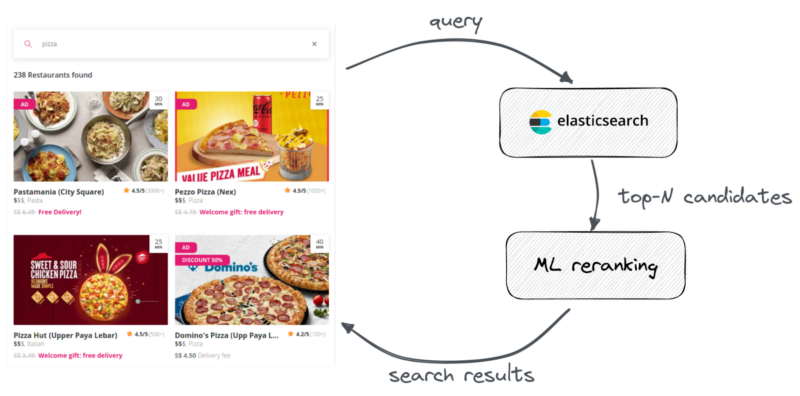
Secondary reranking at Delivery Hero
For more details regarding this approach, check out a talk on E-Commerce search at scale from Amazon at BBUZZ19. To summarize, this technique allows us to strike a good balance between search precision and latency:
- ElasticSearch is excellent at recall and performance, but you can’t do much about the precision of the BM25 similarity ranking model used there.
- But you can take the top-N most relevant documents from ElasticSearch and pass them for further re-ranking to a more advanced ML algorithm focusing on precision, like LambdaMART. It can correlate item metadata with customer behaviour and greatly improve search relevance.
In practice, you can’t make the N value too big: more work must be done for each item, and you can quickly go over the reasonable latency budget for the whole request. A typical N value across the search industry is from 50 to 500 items.
But there’s common wisdom that the deeper your re-ranking is, the higher the chance to improve misrankings of the first-level ElasticSearch retrieval.
Practical LambdaMART
As LambdaMART is nothing more than a special loss function attached to traditional gradient-boosted decision trees, all three major GBDT toolkits have support for this:
- LightGBM has a lambdarank objective.
- XGBoost has rank:pairwise and rank:ndcg objectives.
- CatBoost also has QueryRMSE and YetiRank objectives.
There are plenty of articles discussing the training speed of these toolkits, but in this article, we are primarily concerned with more practical questions:
- Is there a difference in prediction quality between above mentioned LambdaMART implementations on the same dataset?
- If ranking quality is the same (that’s what we were expecting before starting this research), how does inference latency depend on reranking depth and the algorithm’s internal parameters?
As we’re limited by the technology of our time, the ultimate business goal of this research is to increase the depth of the reranking without sacrificing request processing latency (and its quality, of course).

A famous quote from Marvel’s Iron Man 2
Methodology and dataset
We’re going to use a widely-known MSLR WEB10K dataset for the evaluation of different LambdaMART implementations. This dataset features:
- 10k queries from MS Bing
- Each document has 1..5 relevance judgments
- 136 ranking features
But as these implementations are pretty mathematically different internally, we need to ensure that each algorithm’s hyper-parameters are appropriately chosen. So article plan is the following:
- Optimize hyper-parameters for XGBoost/LightGBM/CatBoost LambdaMART implementations.
- Measure latency for different N values.
- Optionally see how the number of trees and max tree depth affects latency.
We’ll use the nDCG@10 as the most commonly used evaluation function for ranking tasks.
Hyper-parameters selection
Plenty of research has been done on how to tune hyper-parameters for Boosted Trees methods. The good thing is that default parameters for each implementation are usually good enough, and there are not so many parameters that significantly affect the quality of the end result:
- The number of trees. The more – the better, as each next tree tries to fix the error introduced by all the previous trees. We won’t tune this parameter directly and use an early-stopping method to prevent over-fitting. When the error on a validation dataset starts worsening for 20 iterations, we assume it’s time to stop.
- Learning rate. The larger the rate, the faster your model trains. But if you go too fast, you may miss an optimal spot and converge on a suboptimal solution.
- Max tree depth. The deeper the tree, the more correlations in the data it may identify, but going too deep may cause overfitting.
Of course, there are plenty of other parameters worth tuning (L1/L2 regularization, sub-sampling, etc.), but we leave them at default values to reduce the scope of this article.

Hyper-parameters for boosters
As we’re optimizing only two parameters at once (learning rate and depth), we can opt for a grid search: it’s not as fast as more innovative approaches, but we can visualize the whole search space!
XGBoost is the oldest GBDT framework on the block and initially supported only an exact tree-splitting method. It gives excellent quality but is prohibitively slow on large datasets. After the initial release of LightGBM, which introduced a non-exact histogram method of growing trees (up to 10x faster than exact!), it was eventually ported to the XGBoost.
We could not complete the HP evaluation with the exact method, as it took too much time, so the results presented here are made with tree_method=hist for the sake of performance. So for XGBoost, the NDCG@10 over different learning_rate and max_depth parameters looks very smooth:
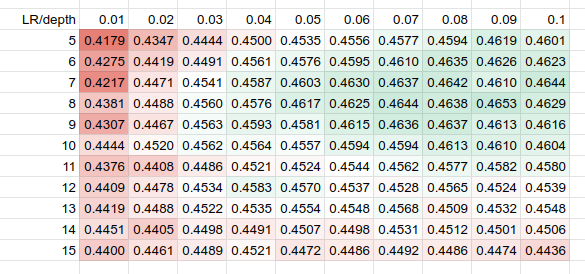
XGBoost eta vs max_depth, NDCG@10
For a LightGBM evaluation, we also made the num_leaves parameter dependent on the depth, according to the formula defined in the docs: it’s min(100, (2^depth / 2) – 1), and the TLDR idea of this parameter:
- The default value is 31, but this number is not enough for deep trees: as there will be fewer splits than needed.
- We don’t want it to grow too much above 100, as the tree may overfit.
- Usually, it should be somewhere around 2^depth / 2.
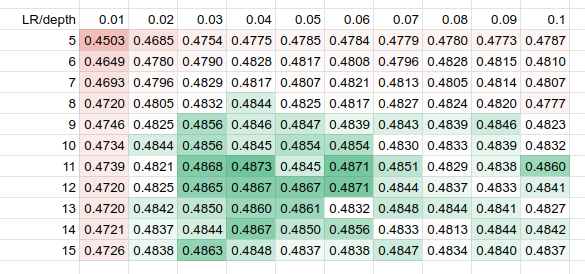
LightGBM learning_rate vs max_depth, NDCG@10
CatBoost is a new kid on the block, and plenty of rumours about its prediction quality exist. But as we’re not affiliated with any authors of these toolkits, we’re trying to be objective. CatBoost has two different widely-used ranking objectives, YetiRank and QueryRMSE – and it’s unclear which one to choose, so we checked both.
As CatBoost uses different tree-growing methods (symmetrical trees going wide vs. imbalanced+deep), we chose a wider range of learning rate and narrower range of max-depth: as growing too deep and symmetrical trees dramatically slows down training.
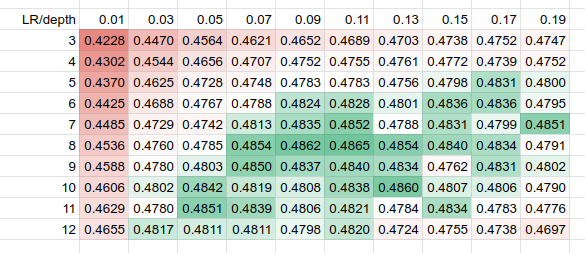
CatBoost YetiRank learning_rate vs max_depth, NDCG@10

CatBoost QueryRMSE learning_rate vs max_depth, NDCG@10
Some general observations regarding the parameter search:
- XGBoost showed significantly worse results, with a value of 0.4653 when both LightGBM and CatBoost were close, around 0.4875. We still don’t have a clear explanation of such a big difference, but the main suspect is the three_method parameter. Another option is the high dimensionality of the WEB10K dataset.
- There’s not much difference between CatBoost’s QueryRMSE and YetiRank objectives on the WEB10K dataset. However, they require slightly different hyper-parameters.
- There’s a death valley on small learning rates below 0.03; the sweet-spot is around 0.05-0.09 for all the boosters.
Overall, CatBoost gives similar results to the LightGBM on the WEB10K dataset, so we can continue researching other practical aspects of GBDT.
Convergence
We used an early-stopping method to prevent overfitting for all three boosters, which is perfectly fine for the hyper-parameter search. But we suspect that the number of trees in the ensemble may significantly affect the target prediction latency, so it’s also essential to see how fast these boosters converge:
- Faster convergence means fewer trees are needed for optimal quality.
- The main assumption is that fewer trees – lower the latency.

So we fixed the learning rate and max-depth parameters according to the optimal numbers we found in the previous chapter and ran training with 1000 iterations:
- LightGBM: LR=0.05, depth=11
- XGBoost: LR=0.09, depth=8
- CatBoost: LR=0.07, depth=10
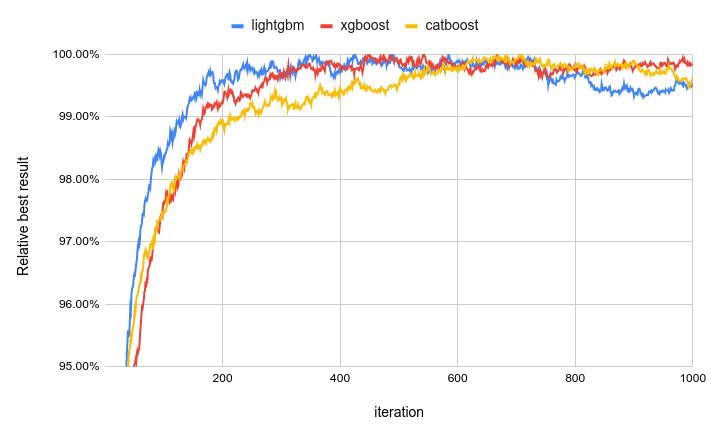
Convergence of boosters on WEB10K dataset by iteration
So it looks like the LightGBM on a WEB10K dataset converges to the best result around the 350th iteration (even having the lowest learning rate!), XGBoost is around the 500th, and CatBoost is around the 700th (but it depends on the learning rate quite a lot!). Main observations:
- There’s usually no reason to set the number of iterations to some ridiculously high number above 1000.
- You can get 99% of the NDCG@10 within just 100 iterations; the remaining one percent will take 5X-10X more.
As CatBoost seems to be an outsider for the convergence speed, we decided to see how sensitive it is to changes to the learning_rate parameter: as a higher learning rate allows faster convergence. The parameter seems to be stable enough when >0.05.
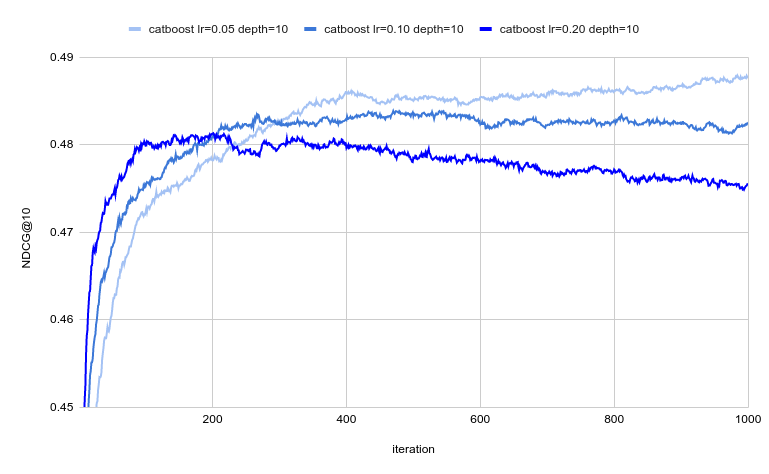
Catboost convergence speed for different learning rates
Indeed, setting a higher learning rate allows the model to converge much faster to a suboptimal solution – so you need to be extra careful with increasing this parameter too high. On huge learning rates, the model starts to overfit noticeably.
Prediction latency
In the Discovery Tribe at Delivery Hero, we have the majority of ranking infrastructure implemented in Java, so it would be most valuable if we measure the prediction latency of different boosters using existing open-source JVM bindings:
- XGBoost: official xgboost4j binding.
- LightGBM: community-maintained LightGBM4j project.
- CatBoost: official catboost-predict library.
Another crucial technical point is that XGBoost and LightGBM are multi-threaded and parallelize over trees with OpenMP when making predictions. This approach works well if you have a low concurrent load, like during the benchmark: a sequence of tasks coming one at a time and plenty of idle CPU cores.
But production systems are very different – they have a very high concurrent load, so multiple parallel requests are usually battling for a shared and saturated CPU.

Multi-threaded benchmarks can distribute workload too perfectly
To solve this problem, we limited the parallelism to only a single thread for each toolkit (by setting OMP_NUM_THREADS environment variable). The comparison will be fairer given the same shared CPU resources.
Before running the benchmark, we should define a plan — a list of assumptions we plan to confirm or break:
- The number of trees (or iterations) is proportional to the amount of CPU usage, so larger models should be slower.
- The length of the reranked item list should also affect the latency. The more items to rerank, the worse the latency.
The numbers we got are the following:
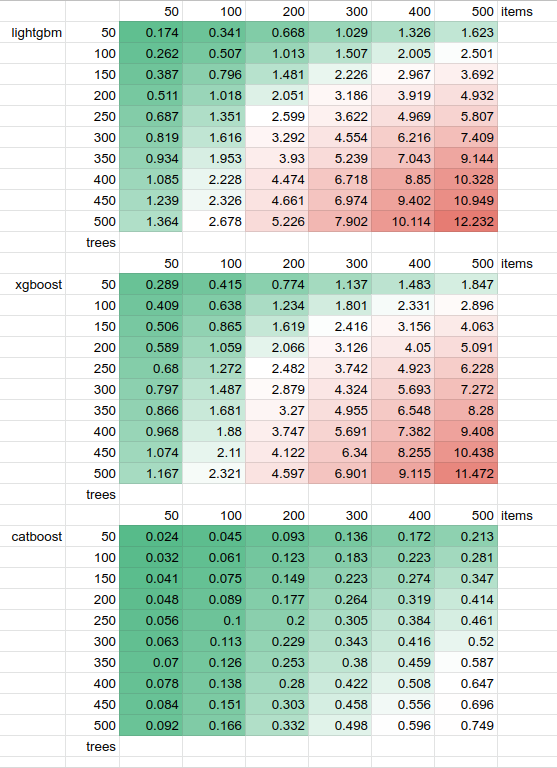
LightGBM/XGBoost/CatBoost latency for different trees/items, milliseconds
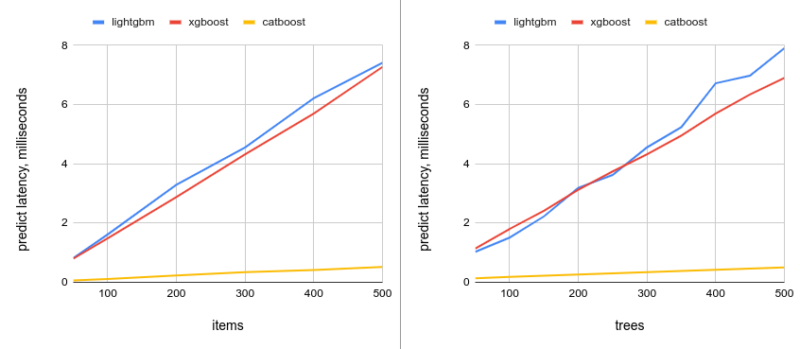
Prediction latency: 300 trees vs items (left) and 300 items vs trees (right)
It looks like CatBoost is MUCH faster than XGBoost and LightGBM in the same setting. We observed a 12X-15X difference in latency on all of the tree/item combinations.
But omitting the parallelism (as we limited all the boosters with a single thread during the benchmark) may give us optimistic hope that in a concurrent setting, LightGBM and XGBoost can be closer to CatBoost, given enough CPU resources. We did such an experiment, and indeed, they became significantly faster:
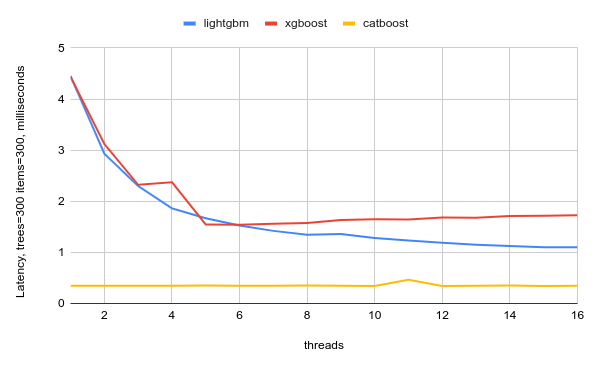
Prediction scalability of LightGBM, XGBoost and CatBoost by the number of threads
The benchmark was done on a desktop AMD Ryzen 7 2700 CPU with 8 physical cores and 16 hardware threads, so in theory, each booster thread should never compete for a hardware thread. The selection of benchmark parameters was done to match the most common values used in the industry:
- 300 trees is the earliest convergence point in the convergence benchmark above.
- As all boosters are parallelized by items (and not by trees), we chose quite a large size of 300 items in the ranking for better CPU utilization.
With extra parallelism, LightGBM and XGBoost become much faster, but CatBoost dominance is still dramatic with a 2X-3X improvement in latency: single-threaded CatBoost is 3X faster than 16-threaded LightGBM.
Training latency
The inference latency results above were too spectacular for CatBoost, so we also decided to see how fast all three booster implementations perform training. Training time usually depends on two factors:
- Max depth of the tree. The deeper the tree, the slower the training.
- The number of trees built.
As time spent per tree is usually constant, we can fix this variable and see how per-tree training time depends on tree depth:
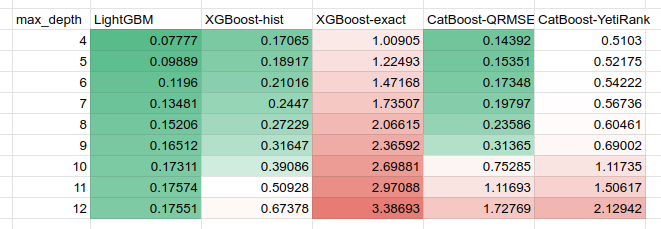
Training latency for different booster configurations
We can observe that LightGBM is way faster than the other two implementations, especially on trees with depth above 8.
- XGBoost with the legacy ‘exact’ three_method is the slowest one, but with a more modern ‘hist’ it gets a significant speed-up.
- As CatBoost builds symmetrical trees, we observed a significant slowdown on deep trees as there are too many leaves per tree generated.
- CatBoost’s YetiRank is quite a complicated loss function, and it takes more time during training to compute it, even for non-deep trees.
Conclusion
The rumours that CatBoost prediction speed is significantly better than LightGBM and XGBoost are true.

CatBoost is unfortunately not about cats but about categorical features
So the main findings of this research are just confirming some crowd wisdom and heuristics about booster implementations, we just confirmed some of them:
- LightGBM/XGBoost/CatBoost are similar in prediction quality if you spend extra time finding optimal parameters. However, parameters are not super stable, so the difference in their default values can be pretty high.
- As expected, prediction latency depends on the number of trees, and the number of items we’re predicting for—more trees and items — more computation needs to be done.
- CatBoost prediction is mainly single-threaded, but even with this difference, it dominates the latency on almost all the tests.
- LightGBM has the fastest training process, even on large tree depths.
As it frequently happens with deep technical questions, the one asked in the title of the article “is CatBoost faster than LightGBM and XGBoost?” has no simple answer. But the numbers we present in this mini-research will allow us (and you!) to make more informed decisions about scaling, costs and latency of our ML workloads.
Would you like to become a Hero? We have good news for you, join our Talent Community to stay up to date with what’s going on at Delivery Hero and receive customised job alerts!






