



Where it all began
Delivery Hero is a listed company with over 45,000 employees in more than 70+ countries, with several thousand employees in IT, and hundreds in data.
The data teams at Delivery Hero are scattered across different regions, countries and companies. At the beginning of 2020, teams used different technologies and several cloud providers and did not share a common infrastructure. The high-quality standards were missing, and as a result, the data quality was often poor. The question of who owns specific data was not easy to answer. The communication between the teams, as well as the exchange of data, was hampered. The proper access management process was neglected, security was solved differently from team to team, data modeling was not standardized and varied from team to team.
The architecture was very chaotic and resembled the image below:
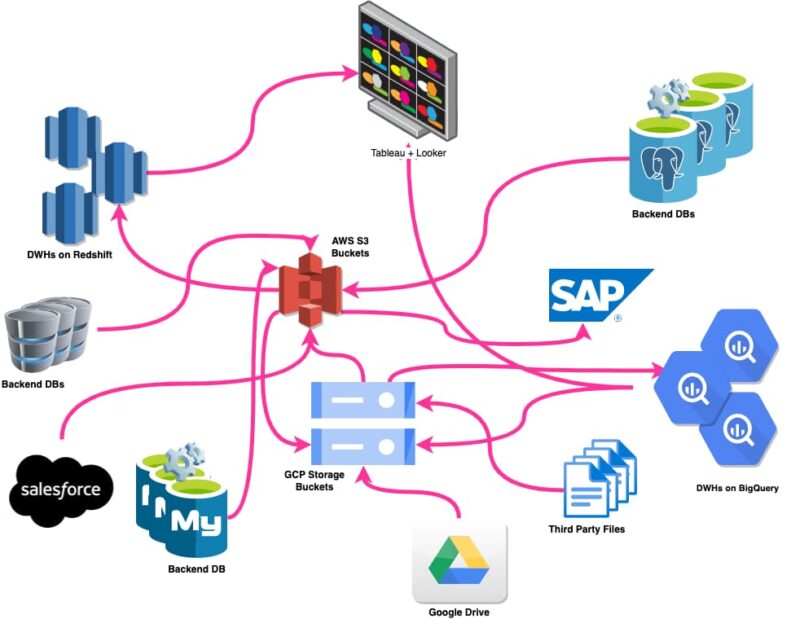
To combine data, perform analysis, and create reports, engineers moved files between different teams, different infrastructures, and cloud providers.
The main issues were data availability, data ownership, access management, data quality, security, GDPR, etc.
Taking action
To begin with, we had to decide what our first priority would be. After brainstorming with multiple data team leads, three primary key points were identified.

The following three priorities were then chosen as top priorities for the first year:
- Scalability of data infrastructure.
- Data protection from unauthorized access.
- Sharing of data access, and a way to combine data across functions.
We knew what we needed to do, but we didn’t know how to structure teams and responsibilities. The Game Changer was an article about Data Mesh written by Zhamak Dehghani.
Data Mesh helps!
Data mesh is a concept that is particularly aimed at large organizations such as Delivery Hero with multiple domain data units. Data Mesh is not a technology and does not describe how to solve a specific problem.
In a nutshell, Data Mesh describes how to organize a team and accountability, in order to build a data-driven organization and create a paradigm shift from centralized ownership to decentralized ownership, from a monolithic approach to a distributed approach, from data as a by-product to data as a product, from the pipeline as a first-class concern to the domain as a first-class concern.
As the basis for this transition, Data Mesh recommends having a data infrastructure as a platform.

Link to resource image
This platform should provide support for multiple Domain Data teams within an organization. Now let’s look at how this platform was built at Delivery Hero.
Data Hub is a unified analytics platform at Delivery Hero
Finding scalable and future-proof solutions with the ability to easily exchange data without having to physically move data between different cloud providers or teams was not easy. The decision-making board goes through several interactions and comparisons about existing internal solutions. Some of the teams used solutions based on Redshift+Airflow/Jenkins, others on BigQuery+Airflow.
BigQuery
After months of comparing the advantages and disadvantages of both big data engines, the decision was made in favor of BigQuery. At this point, half of Delivery Hero’s data teams were already using BigQuery. The biggest benefit of using BigQuery was the ability to use a SQL JOIN between different projects, without having to move data physically. Considering the enormous amount of data that Delivery Hero has already in different projects, this argument was disproportionately strong.
Status Quo
Next, we considered which team already using BigQuery has more technically oriented solutions. The decision finally fell on the solution developed by Logistics BI, one of our tribes. This project was the starting point. Massive thanks to this team – they inspired this whole project!
None of the solutions fully ran on GCP. Logistics also used a heterogeneous setup of BigQuery on GCP, and a Kubernetes cluster on AWS. As the main idea was to unify all data teams as soon as possible, all teams started moving their data to BigQuery in the central project. As this infrastructure was originally developed for one team, we soon encountered limitations and started with the platform review.
Challenges
The biggest challenge was making this platform scalable for multiple teams, while also considering whether Kubernetes clusters on AWS still make sense when the data engine for this project is going to be BigQuery. After the proof of concept, the decision was made to rebuild the entire infrastructure on GCP, with a focus on scalability.
The idea was to provide a powerful environment, with the possibility to manage and auto-scale Kubernetes clusters, to deploy multiple dedicated Airflow environments (prod, staging, development), with the possibility to use airflow plugins and extensions. It also needed to be protected with the highest security standards – and last but not least, beat GCP Composer! 🙂
The GCP project structure made it possible. Each data team, which we call Domain Data Unit corresponding to Data Mesh terminology, is provided with a dedicated GCP project with all the necessary components such as BigQuery, VPC, Kubernetes Cluster, CloudSQL, Load Balancer, Secret Manager, Monitoring, etc…
Architecture
After two months of initial development with the newly established Data Hub team, along with the help of a Google partner consulting firm, we built initial infrastructure on GCP and began migrating multiple teams from AWS to GCP. From the beginning, this project was seen as an internal open source project, to which all data entities can contribute. Many decisions were made in a very open atmosphere, and after long, sometimes highly debated discussions. The focus was on building a platform that covers all of our use cases. As a result, the following platform was created:

The entire management of the projects comes from infrastructure projects like control and storage, which includes GKE, VPC, Container Registry, Secret Management, etc., and projects for development and staging. On the domain data units side, there are dedicated projects, one per team, where Airflow environments get provisioned by the Kubernetes cluster. The domain data unit team (DDU) gets fully installed and configured in production, staging, and multiple development environments.
This allows teams to work independently, and also allows team members to use a remote development environment without having to install it locally. All Airflow URLs are protected with SSO. Deploying a new DDU currently takes less than two hours. To manage access requests, we use a Jira-based service desk with two permission levels for regular and PII data access.
The PII columns are protected in BigQuery with the column policy tag. The data is accessible via Google Groups and is managed via an ACL file. As this manual process still takes a lot of time, the Data Hub team is already working on a fully automated solution to reduce the time it takes team members to access data. One of the possible solutions currently being discussed is Sailpoint, in combination with Google Roles/Groups.
Outlook
For the next year, the Data Hub team plans to focus on the following main topics:
Machine Learning
The next big topic is the integration of Machine learning into Data Hub. We are planning this in two ways:
- Through better integration of the VertexAI (Google Cloud Service) into the existing platform.
- By using Data Hub infrastructure to provision resources for ML models.
Data access management automation
At the moment, data access management is a very stable service desk process. The downside to this process is that it is currently mostly a manual process. Data engineers spend a lot of time granting access to consumers. To streamline access management, the process needs to be automated. It requires an evaluation of existing solutions or in-house developments.
Compliance and Security
One of Data Hub’s main goals is to provide consumers with a safe and secure environment. To achieve this, the data hub platform was assessed by an external and an internal audit team. This process and the associated improvements are continued at regular intervals.
And many other topics...
We plan on working on a number of other exciting topics during the coming months as well.
Some Data Hub KPIs

Conclusion
The Data Hub platform provides a lot of value for the company and has become one of the core projects at Delivery Hero during the last year. It helps domain data units to share data between different teams and tribes, analyze data at a large scale, and ensure data quality. Finally, it helps Delivery Hero make the right decisions.
Team
Data Hub is an exceptional project, and one of the first in the industry with the proper integration of the Data Mesh concept. The future of the industry is being shaped here and now. This fantastic result was possible because of the great professionals, data, platforms, and systems engineers behind this work. Thanks to the team for this incredible achievement!
About the Author
Pavel is the Director Global Data platform. He joined Delivery Hero through the Foodpanda acquisition in 2017. Today his main focus is to provide the global data platform based on Data Mesh principles for Delivery Hero, enabling it for several hundred data engineers, analysts, and data scientists around the globe.
Helpful links
- Zhamak Dehghani: Data Mesh Principles and Logical Architecture
- Data Hub success story on the Google Cloud homepage
Glossary
- Data Mesh – is a concept, principles, logical data, and organization architecture best suited for enterprise companies
- DDU – Domain Data Unit can be an existing team of data engineers, analysts, or data scientists
- GKE – Google Kubernetes Engine
- VPC – Virtual Private Cloud
- PII – Personal Identifiable Information
- SSO – Single Sign-on
- ACL – Access Control List
Interested in working with us? Check out some of our latest openings, or join our Talent Community to stay up to date with what’s going on at Delivery Hero and receive customized job alerts!




