



Testing mobile apps at Delivery Hero was challenging due to heavy reliance on a real environment for running E2E tests. This article explains our story of solving the problem of all mobile devs being blocked from merging their code due to the failure of E2E tests in the real staging environment.
The staging environment hosts numerous backend services and was prone to issues like downtime, configuration mismatches, and data corruption which resulted in complicating the testing process.
In the fast-paced world of mobile app development, ensuring the quality and reliability of the application’s backend interactions is crucial. However, relying on an unstable environment to test apps can have adverse effects, leading to low developer confidence while running tests and also impacting release quality.
Mockingjay is a game-changing tool for all mobile engineers. It empowers them to streamline API mocking without removing the network layer which helps them connect with a remote server for API calls. It creates a stable environment to test their code.
How did we get here?
The major reason for us to look for a mocking solution was to reduce the dependency on teams, their environments, and the test data changes happening frequently in the testing environment. In large organisations such as ours, many teams work in different timezones and can deploy their changes or change the test data which results in client test failures.
This was a big challenge for us, as our CI pipeline would fail every 1 to 2 hours and everyone had to wait for the API fix or the test data restoration. This was neither scalable nor sustainable, as it meant every time someone sitting on the other end of the world deployed one change, it affected all the mobile engineers until the fix was made.
On-demand deployment model works well for backend services, but from the client’s perspective, this creates chaos and mayhem. Frequent deployments by different teams made it difficult to maintain the sanctity of the test data and the testing environment.
We knew that the E2E tests were not going away and spinning up a new testing environment wasn’t an option. This was due to the cost implications, the necessity for third-party integrations in the new environment, and the complexity involved in its management and maintenance. At that point, we started to look for alternatives.
The Study and Analysis
Before we could analyse any tool, we had to comprehend the types of API calls that the apps were making and what they were used for. We catalogued all the API calls made by the mobile clients and recorded their responses, aiming to understand how and where they were being used.
We started keeping track of how frequently all app engineers encounter a failure that is beyond their control and for which they must wait for the backend or third-party tools to fix. This helped us assess whether mocking was the best course of action for us, or if we needed any other solution to this problem.
Exploration
We began exploring open-source and ready-to-use solutions available in the market. Our major considerations during the tool exploration were the following:
- The learning curve required to understand the tool
- The customizations the tool allows for integration with our backend services
- The ease of use in integrating with our existing setup
The two candidates that stood out were – OpenAPI Spec and mock-server.com.
Challenges with OpenAPI
- We had more than 1,000 test cases, and it was impossible to maintain all these different responses within OpenAPI.
- Another issue was running the stateful test cases. OpenAPI did not allow clients to request response A to be sent after response B.
- Additionally, as of 2020, the OpenAPI spec did not support custom expectations to be set for API calls.
Challenges with Mockserver.com
- Mockserver did not support non-HTTP protocols. Since mock-server.com is an open-source tool, we had to wait for the implementation of bug fixes and enhancements.
- In 2020, Mockserver did not permit the modification of headers or any values within its proxy.
Other explored options, including WireMock, and Postman, fell short of our needs, leading us to decide on building an in-house solution.
Solution
MockServer v1
The mockserver v1, our in-house mockserver, allowed engineers to use this server as a dictionary of API requests and responses. Engineers had to use network logging tools to identify the API calls that were being made during the test execution. For E2E test case run, Mockserver v1 relied on API paths and unique identifiers added to these API calls to return responses.
In the implementation of mockserver v1, developers added the curl requests for each API call to the admin dashboard and assigned each a unique name. The infra team provided a default response for each API request, with additional curl requests supplementing this default response. Once all the required request responses for a test case were added to the admin dashboard, engineers could then map these requests to test cases.
Feedback and Challenges
Following the roll-out of mockserver v1, we gathered insights and feedback from engineers to understand its performance and impact. One really good thing was the feedback in terms of the stability of our Continuous integration pipeline. We had almost zero instances of builds being blocked because of environmental instability.
We also received the following valuable feedback on what were the challenges in using the mockserver v1.:
- Developer Productivity: While mockserver v1 was powerful in terms of stability as we had almost no downtime, it came in with a high developer productivity cost. To migrate one E2E test case running on a staging server, engineers spent more than 1 day recording all curl requests and then mapping them one by one to each of the test cases.
- Concurrency Issues: The mockserver v1 used the API path and the unique names added by engineers to identify the responses required by a test case. The challenge here was that some of the API paths, even though the same, expected different responses based on the request body, request query params, and the state at which the APIs are called. As mockserver v1 only relied on the API path and unique name it struggled to identify the uniqueness of these nuanced requests, often sending incorrect responses to clients.
- Learning curve: While mockserver v1 was easy to use, it required engineers to know all the APIs being used in their test cases. This was necessary because the system needed all API requests to be mocked, a process involving manually copying curl requests and adding them individually to the admin dashboard.
Mockingjay (Mockserver v2)
Mockingjay(Mockserver v2) is an enhancement of the previous mockserver version. Responding to the feedback received from engineers on mockserver v1, we adjusted our solution, leading to the creation of Mockingjay —a powerful mock server designed to serve Mobile client apps seamlessly. With its impressive features and ease of use, Mockingjay has revolutionized how engineers handle API mocks for E2E tests.
Key Features of Mockingjay
- Effortless API Traffic Recording: With Mockingjay, engineers can say goodbye to the manual process of recording API traffic. Acting as a middleware, Mockingjay automatically captures and records API requests and responses. This feature eliminates the need for tedious and time-consuming setup, allowing you to focus on building and testing the app’s core functionality.
- Realistic Test Cases: Maintaining a healthy test suite that closely resembles the real implementation can be a daunting task. However, Mockingjay simplifies this process by providing a seamless way to mimic API behaviour. By using Mockingjay as a mock server, you can closely replicate real-world scenarios and ensure your test cases are reliable and accurate. This capability proves invaluable, especially when dealing with external services that may be unpredictable or inaccessible during the development phase.
- Independent Test Data: One of Mockingjay’s standout features is its ability to provide each test case with its own set of test data. Unlike many other mock servers that rely on commonly shared data, Mockingjay offers an isolated environment for each test, guaranteeing independence and preventing unwanted interference. This flexibility allows engineers to create comprehensive and targeted test cases, ensuring that all possible scenarios are thoroughly examined.
Diving Deep
High-Level Architecture
Let’s now understand the high-level architecture of Mockingjay. When you run your test case locally, the API requests are sent to Staging via Mockingjay, which forwards those API requests to staging services, stores the response received from staging in its database and then forwards the response to clients.
Once the test case execution is complete and the response is correctly recorded, in the next execution Mockingjay retrieves the responses stored in the database, saves them in the Redis cache, and then returns them to the client. This enhances the performance of the service as the next time the test is executed, it fetches the response from the cache and sends it to the client within milliseconds.

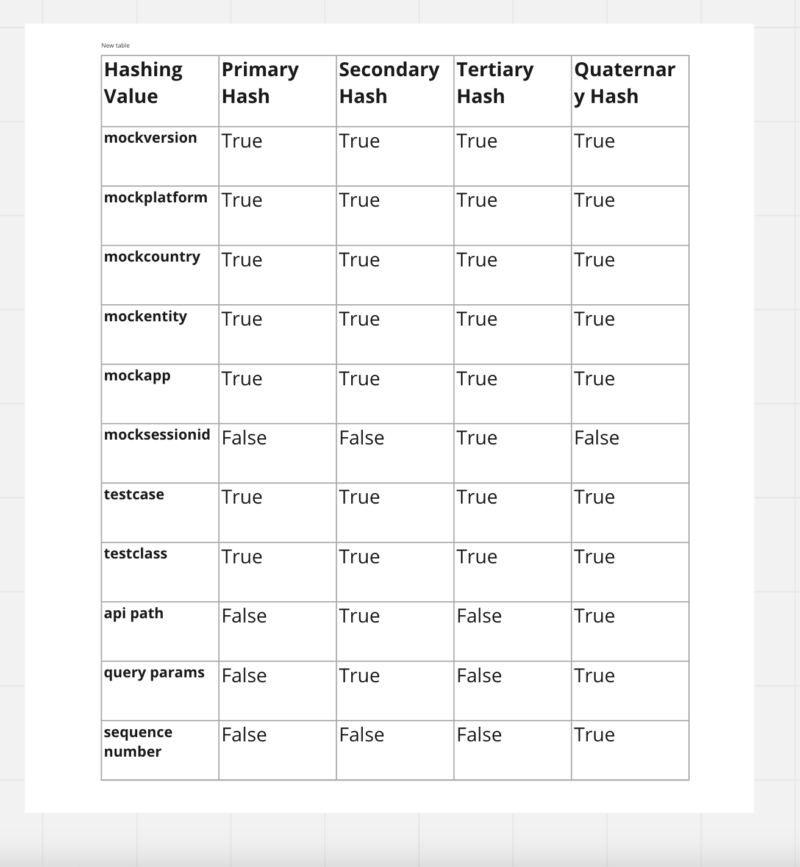
Hashing
We use tailored hashing logic to uniquely identify a test case and API calls.
- Primary Hash: Uniquely identifies a Test case and test state.
- Secondary Hash: Uniquely identifies API calls by their paths.
- Tertiary Hash: Uniquely identifies a test case recording or replay session.
- Quaternary Hash: Uniquely identifies an API call.
The below table shows the request headers used to generate different Hash Value:
Test Case Life Cycle
Mockingjay streamlines a test case’s lifecycle by dividing it into four distinct phases:
- Organic Phase: In this initial phase, the test case is created and defined based on the desired behaviour of the API. This phase acts as a blueprint for the subsequent phases.
- Recording Phase: In this phase, Mockingjay automatically records the API traffic based on the test case’s specifications. Every request and response are captured, forming the foundation of the test case.
- Editing Phase: Once the API traffic is recorded, engineers can fine-tune and modify the test case as needed. This phase allows for adjustments, such as adding custom responses or tweaking parameters, to ensure the test case accurately reflects the desired behaviour.
- Replay Phase: The final phase involves running the test case using the recorded API traffic and the defined modifications. This allows engineers to validate the app’s behaviour against the mocked responses, ensuring that it performs as expected and handles various scenarios effectively. The replay phase has 3 options:
- Using Sequence Number: This means that during the test recording phase if /api/v1/deliveryhero is called 4 times, we assign an order number to this API call and generate a unique hash using this order number.
- Using an Expected Response ID: This option is used when you are unsure about the number of times APIs will be called and also when you don’t want to worry about the query parameters. e.g. during the recording phase, if /api/v1/deliveryhero was called 3 times but you feel that due to retry logic or other reason it might be called 5 times then you are at the right place and you should use this option. In this case, you will set the response IDs for this API call on the client side and the client will then get the response that it has requested. The client has a custom method called overrideAll(“/api/v1/deliveryhero”, 25). In this case, the client will receive the response with ID 25 if it is called 1 time or 50 times without any additional delay.
- Using Expectation Matching: With this option, developers initially set the expectations for the API call, based on which Mockingjay determines the appropriate response to send. We have developed a custom dashboard that enables developers to set expectations without making changes to their client-side code. This dashboard accommodates all headers, API paths, query parameters, and request body data for expectation setting.

Benefits of Mockingjay
By incorporating Mockingjay into our testing workflow, we experienced several significant impacts on the app development process:
- Improved Development Efficiency: With Mockingjay’s automatic API traffic recording and realistic test case generation, engineers can save valuable time and effort. They no longer have to manually create and maintain mock data or rely on external services, enabling them to focus on building and iterating their app’s core features.
- Reduced Dependency on External Services: Mockingjay reduces the dependency on live APIs or external services during the testing phase. Engineers can continue their work uninterrupted, even when the services they rely on are unavailable or still under development. This independence promotes faster development cycles and mitigates potential bottlenecks.
- Increased Testing Stability: The median success rate (p50) for the staging environment is 45% whereas Mockingjay is at 84%. Also, Uptime for the Mockingjay server has been 99% since its inception.
- Increased Testing Flexibility: Thanks to Mockingjay’s independent test data feature, engineers can create targeted test cases without relying on commonly shared data. This allows for precise testing of specific scenarios, making it easier to identify and fix bugs or edge cases early in the development process.
Conclusion
One of the great things about Mockingjay is that it can also be extended to be used by backend services. By incorporating Mockingjay into our testing process, we have achieved a higher level of stability for our CI builds. Mockingjay has led to improved delivery cycles, enabling more extensive and reliable testing.
If you are interested in knowing more about our experiences, feel free to get in touch with us on LinkedIn: Ankit Khatri and Shrinivas Khawase.
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.





