



Introducing the automated system for reliably and swiftly serving AI services, developed by the AI Platform team at Woowa Brothers.
Nowadays, it’s quite common to see robots serving food in restaurants. There are many steps involved in getting the food to the table such as preparing the ingredients, cooking, and finally serving. With the help of serving robots, restaurants can save time for serving and focus more on cooking.
The process of building AI models, training them on data, and deploying them as services is similar to serving food in a restaurant. Without having to care much about the deployment process into the production environment, we can concentrate solely on training the AI model.
Woowa Brothers’ AI Platform has an automated serving system which takes care of the model deployment and management once an AI model is created. Let’s have a look at how we have set up our automated serving system.
What is the AI Platform?
Incorporating AI technology into a business requires a lot of different technologies. Various components are intricately intertwined, from data management to pipelines for model training, and serving processes that enable the use of AI models.
Woowa’s AI Platform organically combines all these components, making it easier to use. The environment of Woowa’s AI Platform is shown in the diagram below, which was also shared in the Tech Blog post “Baemin app also provides AI services? Introduction of AI services and MLOps.”

Here, the serving process refers to providing the trained AI model as an API so that it can be deployed into the production environment, enabling users to place inference requests in real time. The AI Platform involves optimization of the AI model to ensure faster response in a stable manner, covering API creation, scalability management, version control, and monitoring, among others.
It is important to serve AI models stably and quickly since large volumes of data are created daily, with new AI models constantly trained using this data. Currently, the AI Platform’s serving system handles about 2 billion requests per month. For a stable serving system, model version control, zero-downtime deployment, and rollback actions must be carried out thoroughly. Since this blog will cover the serving environment, let’s assume that the trained AI model has been stored in the Model Registry, a repository that can manage the versions of AI models.
Serving component
AI service developers train AI/ML models using various frameworks and libraries such as PyTorch, TensorFlow, CatBoost, and scikit-learn. However, when it comes to serving, models based on different frameworks may have different loading methods or inference functions, making it difficult to maintain code consistency, resulting in complicated maintenance and increased system complexity.
To address these challenges, the AI Platform was built by adopting BentoML, which supports multiple frameworks and rapid development for model serving. BentoML makes it easy to support containerization, facilitating smooth deployment on Kubernetes and allows for quick addition of business logic such as preprocessing and postprocessing, enabling fast service configuration.
The following code shows an example of serving an AI model using BentoML on the AI Platform.

By writing a simple code like the example above, you’ll be able to provide an API that returns the inference results when called via /inference path. The rest will be taken care of by the AI Platform, automatically. As a result, AI service developers can focus only on the development of the model, which speeds up the development and helps maintain code consistency. Now, let’s have a look at how we were able to automate the remaining tasks.
CI (Continuous Integration): Automated image generation
When a service code like the one above is pushed to the GitLab code repository, it goes through various tests in the GitLab CI pipeline to generate a docker image. Woowa’s AI Platform uses the monorepo approach, which manages all services in a single repository. The CI is set up in a way that dynamically creates pipelines so that additional tasks are not required when creating new services.

In the process of generating images, models are added within the image. Although this takes longer to build and takes up a significant amount of data, it offers greater stability by avoiding the risk of a single point of failure (SPOF)-where a failure of a single component could potentially lead to the collapse of the entire system–by not connecting to the Model Registry. Also, there is no need to match the serving logic with the model version, which enables rapid recovery in case of issues and reduces code complexity. The generated images are stored in the Docker Registry and subsequently deployed to the Kubernetes environment.
The versions of each service are managed using semantic versioning, such as 2.5.3. As shown in the diagram below, semantic versioning divides the versions into {Major Version}.{Minor Version}.{Patch Version} to manage the impact of the changes more intuitively.

In the case of building images in the CI pipeline mentioned above, there would have been code changes. If there are only changes to the logic, there will be minor version changes (2.5.3 → 2.6.0), and if there are changes to the API input/output, there will be major version changes (2.5.3 → 3.0.0). Models can be retrained on a daily basis or with a specific cycle using new data. When a model is newly trained with the retraining pipeline, the patch version will be updated (2.5.3 → 2.5.4).
As the deployment of modified minor/patch versions will cause no significant issues, a zero-downtime deployment is performed as a rolling update, which is a gradual update without any downtime. However, any major version changes will not be integrated with the existing API. Thus, we have set up the CI pipeline to leverage oasdiff, a tool used for comparing and identifying the changes in the OpenAPI specifications, to detect any breaking changes that might be incompatible with existing versions due to newly created APIs. For such cases, we use the Blue-green deployment method, which is migration from an existing environment to a new environment. Manual deployment is conducted by switching the API calls to the new version and deleting the previous version once the new version is created.
CD (Continuous Deployment): Automated model serving
The API is then deployed to a Kubernetes environment, the configuration of which is shown in the diagram below.

Each service has its own designated namespace, and containers are deployed as pods using Deployment. The scheduling system dynamically allocates resources to the deployed pods. Replicas are increased (scaled out) when there is an increase in calls, and reduced (scaled in) when there are fewer calls.
The user’s call passes through Ingress and Service and is then delivered to the destination pod. Ingress traffic goes through AWS’s Application Load Balancer (ALB), which automatically scales its capacity to match the volume of incoming requests. Then, Route53 automatically registers the domains and creates separate endpoints for each service.
The nodes on which a pod is deployed are determined by Karpenter, an extension tool that automatically provisions and manages the necessary nodes to meet workload demands. NodePools define groups of nodes with specific properties, enabling automatic allocation of the appropriate resources based on workload requirements. As EC2 instances that meet resource requirements are defined for each NodePool, each service selects which NodePool to use. When a new pod is created, it will be allocated to an available node within the NodePool. If all nodes are unavailable, Karpenter provisions a new EC2 instance, as defined in the NodePool, to create a new node.
Kubernetes specifications are all managed through Helm (the package manager for Kubernetes applications). One key advantage of Helm is the flexibility to define a common template, which can be customized with specific modifications for each service. The charts created from these templates are deployed using ArgoCD (a tool for automating application deployments and management) while Git is used to organize and manage the deployment specifications.
In particular, ArgoCD Image Updater plugin was used to automatically deploy updated Docker images when changes are detected. It monitors image tags and triggers a rolling update whenever a minor/patch version is released. This fully automates the entire process from image creation to deployment, enabling efficient operations.
Monitoring and Alerts
On the AI Platform, we monitor the metrics of both the serving infrastructure and individual services using Grafana. Additionally, Prometheous is used to monitor metrics within the Kubernetes environment and BentoML, while ALB metrics are monitored with CloudWatch. DCGM Exporter monitors services that run on GPUs.
Below is a part of the monitoring system configured on the AI Platform.

Instead of creating one dashboard per service, we created a single dashboard that features multiple services. Users can choose a service from the upper-left corner of the dashboard and view the metrics that correspond to the said service. In Variables, the service_name is generated by utilizing the same format as namespaces in the Kubernetes environment, such as serving-sample-project-beta. As shown on the right side of the picture, queries are run using the regular expression serving-(.*)-beta. This allows the user to get all namespaces currently in use and extract the service names such as sample-project through filtering.
The serving alert system for the AI Platform can be largely divided into two types: infrastructure alerts and service alerts. Infrastructure alerts are notifications about the AI Platform, usually informing about system issues, and are therefore handled by AI Platform developers. On the other hand, service alerts are alerts required by each service, which usually involve logic issues, and are resolved by AI service developers.
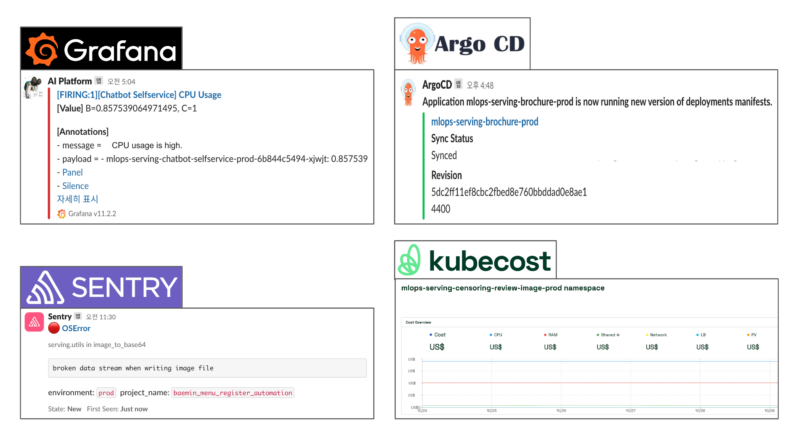
For infrastructure alerts, there is a Grafana dashboard to monitor the infrastructure status and an alert is sent when metrics exceed their respective thresholds. For example, alerts are sent when the CPU/memory usage exceeds the set threshold or when there are no requests for a certain period.
One type of service alert is deployment alerts, which notify users when ArgoCD has automatically completed a deployment. Meanwhile, error alerts are detected and communicated by Sentry, which aggregates information when there is an issue with the logic, allowing users to easily deduce the type and nature of the error based on trace information. Lastly, Kubecost provides a view of the approximate cost for each service, which helps us ideate ways to optimize costs for each service.
Challenges encountered in production and solutions
The following are some challenges we encountered while configuring the serving environment. Let us share our experiences and lessons learned, which may help you in similar circumstances.
1. Intermittent response errors due to Keep Alive
While running our services, we occasionally observed 5xx errors in ALB as shown below in the image on the left. It wasn’t a major issue as a retry logic was in place, but it did require a quick fix. After some analysis, we deduced that Keep Alive was the likely culprit.

The Keep Alive feature configures a system to maintain the HTTP connection alive, allowing multiple requests to be sent over a single connection. It improves performance by enabling multiple requests/responses to be handled without having to reset the connection. The connection is alive until it reaches a timeout, which is 60 seconds by default in ALB in the case of Woowa Brothers. BentoML does not provide an option to set the timeout, so until now, it leveraged the default 5-second timeout in Uvicorn (web server in Python that supports the ASGI standard), which is the ASGI server used in BentoML. In short, the server timeout was shorter than the ALB timeout, which ultimately caused the error.
As shown in the image on the right, the connection is terminated after 5 seconds, which is the timeout set by the server. However, as the ALB timeout is set to 60 seconds, there is a time gap during which the system fails to recognize that the connection has been closed, causing subsequent requests to fail. To prevent errors due to connection termination, the server’s timeout value must be greater than the timeout value in ALB. However, since BentoML does not provide the option to configure the timeout, we created a PR(feat: add uvicorn timeouts options) to add this feature. With the new feature in place, we were able to solve the intermittent errors.
2. Response errors during rolling update due to sync delay between pods and ALB
Response errors were observed during the retraining and rolling update of AI models, which had to be reproduced to identify the root cause of the issue. The image on the left shows several redeployment attempts and it errors when the request unexpectedly drops midway. This was an issue caused by the difference in lifecycles of the pod and ALB Target Group, which resulted in a delay.

When a new pod is scheduled and ready, the existing pod is deleted. Here, when ALB is used, the Target Groups are updated simultaneously. However, the Target Groups may not be ready, and therefore, unable to receive or process any requests. To avoid this, a Readiness Gate (a setting that does not allow traffic until the pod meets certain conditions) was configured, which ensures that the existing pod is deleted only when the Target Groups are ready.
While the Readiness Gate solves traffic issues when creating new pods and Target Groups, traffic problems may still remain when deleting existing ones. For instance, even after the existing pod is deleted, the Target Group may not be updated in time and thus be unable to receive requests. To prevent requests from being sent to an unready Target Group, a delay in the pod shutdown process must be added. This can be done by introducing a forced delay logic in the preStop hook (a hook that triggers a specific action before the pod is shut down). Setting a sufficiently long delay (30 seconds as of now) gives the Target Group enough time to update, thereby avoiding any traffic issues.
If a delay is configured, the extra time allows the Target Group update to complete, making the Readiness Gate unnecessary in this scenario. In conclusion, setting an appropriate delay when the pod is deleted helps prevent any traffic issues altogether.
3. BentoML memory leak bug
Once an alert was triggered, notifying us of increased memory usage during a version update of BentoML, we investigated the issue. Upon closer inspection, it became evident that a memory leak was occurring, as the memory usage gradually increased over time, as shown in the image below. We attempted various configuration changes to identify the cause, but the issue persisted.

The issue persisted even after we stripped down most of the internal logic or used Runner exactly as it had been in the previous version. The memory leak continued to occur, even with the tutorial sample code, which contained no logic. This helped us pinpoint that the problem was with BentoML itself, rather than our logic.
Here, we reported the issue(bug: memory leak when I am using bentoml>=1.2) to the maintainers to keep them informed of the situation and continue the communication. It became a back-and-forth process of receiving test ideas, running the tests, and then sharing the results again. After several iterations, we discovered that the issue stemmed from a newly added file-related feature that was malfunctioning. We were able to fix the flaw and resolve the issue.
It was an enriching experience to actively communicate and brainstorm different options for solving the problem. If it’s a simple fix, contributing directly to open source is quicker, as in the case of the Keep Alive issue. However, for more complex problems, it’s better to actively report the issue to the maintainer, trusting that they will assist in resolving it.
Conclusion
So far, we have seen how the serving automation system is configured in the AI Platform of Woowa Brothers. The vision of Woowa’s AI Platform is: “Until the day everyone becomes an AI service developer.” In other words, the main purpose of the AI Platform is to create an environment where anyone can easily and quickly develop and serve AI services.
Moving forward, we plan to develop a UI that enables users to easily create and modify services on a webpage. Our ultimate goal is to build an AI Platform where users can simply describe the features they need, and the system will automatically create a complete service from start to end.
Stay tuned to see what the future holds for our AI Platform! 🌈
Please note: This article is an English translation of the AI Platform team’s blog post titled “Stable AI Serving System, with a Touch of Automation” originally published in November 2024.
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.



