



Serving promotion campaigns for a large number of items and stores across multiple platforms is very complex. This blog explores the challenges Delivery Hero’s Quick Commerce team faces in maintaining promotional consistency across multiple touch points, price dynamics, and timely activation, as well as how upcoming solutions, like GraphQL sub-graphs and a unified source of truth, aim to address these issues.
At Delivery Hero, we are serving hundreds of thousands of promotions (± 500,000 globally) across different platforms simultaneously, with up to 700,000 products (sku per vendor) in each. Ensuring they execute seamlessly is a very complex challenge. This challenge becomes even more pronounced as the volume of promotions increases with the number of vendors we onboard and the size of their assortment. In this blog, we’ll dive into the current challenges in promotions execution and share the steps we’re taking to streamline the process.
Understanding the Current Challenges in Promotion Flow
Price Dynamics
Price changes are a significant issue. When running a strikethrough promotion, prices need to be updated in real-time across all platforms. However, current systems allow only one price attribute per product at any given time. This means the unit price has to be updated immediately when a promotion starts or ends, so the user has an actual price value in a given period of time, which can be difficult to manage efficiently.
Multiple Data Sources
One of the main issues we face is handling promotions that rely on different services, including product listings, carts, and search functionalities. This fragmentation creates data inconsistencies, where customers may see a promotion banner but not the correct discounted price, or where products under promotion aren’t properly displayed.
Ensuring that promotions run smoothly across these multiple services requires synchronising data like discounted prices, promotional labels, and banners. Without a unified system, keeping this data consistent is a massive challenge.
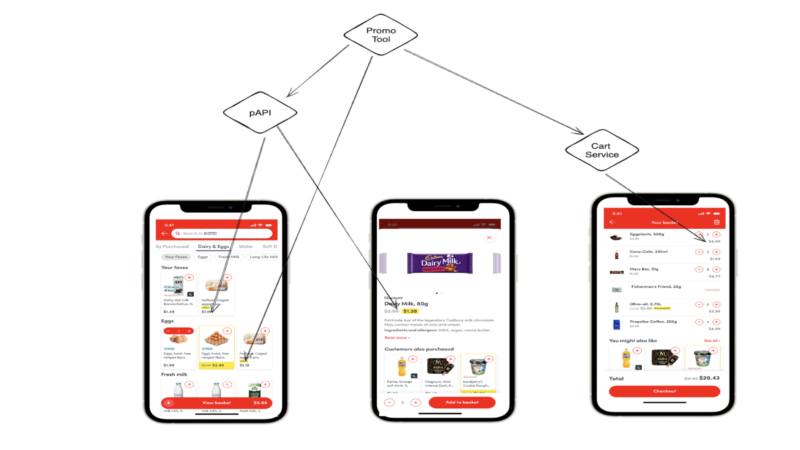
Development and Maintenance Limitations
Double Development
Currently, both our Promo Tool and Cart Service handle promotions separately, using different data sources. This often results in duplicated efforts, such as managing overlapping SKU targets or A/B testing configurations, making the system harder to maintain, and leading to inconsistencies.
Expensive Maintenance Support
The complex web of data services and storage systems increases the chances of errors. For instance, prices can sometimes mismatch between product listings and carts, or a promotion may not display properly in the app, leading to poor user experiences.
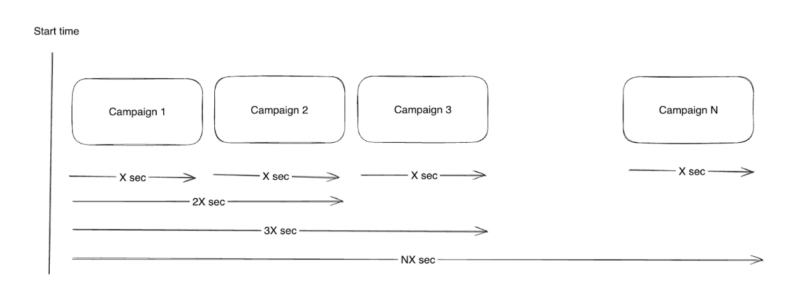
Promotion Start Times
Promotions need to be activated sequentially at precise times, which becomes challenging as the scale grows. If a promotion doesn’t start at the same moment across all services, customers can experience delays in seeing the right discounts. This leads to data discrepancies, with some promotions appearing incomplete or inaccurate in the app, as well as missed opportunities for our consumers and therefore for us as well.
How We’ve Moved Forward
Our Vision of Promotions Life Cycle
To solve these challenges, we’ve introduced a more structured promotion lifecycle. This vision introduces a high-level flow broken into three stages: Ingestion, Processing, and Execution. Each stage is designed to optimise the way we handle promotions, from initial setup to real-time application.
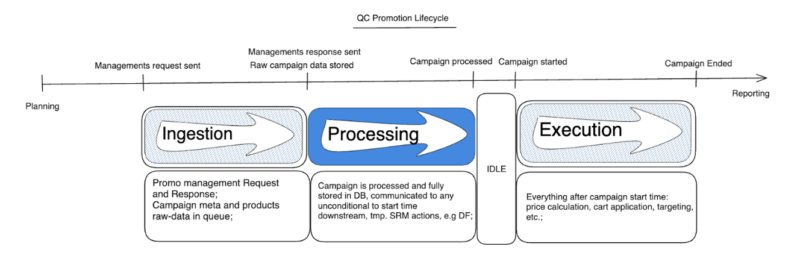
Ingestion
The Ingestion stage is the entry point for all promotions. It manages incoming promotion requests, stores raw promotional data, and places the promotion into a pending state for further processing.
Processing
During the Processing stage, the system takes the raw promotion data and moves it from the pending to the processed state. Here, all relevant promotional data is saved to appropriate databases (e.g., Redis, cache), and any time-independent events—such as sending data to streams—are triggered. This stage prepares the promotion for execution, ensuring that all related information is accurate and ready to be applied.
Execution
Finally, the Execution stage is where the promotion is applied in real-time. It handles everything from calculating discounted prices in the cart to updating the frontend with promotional labels and banners. This stage operates from the start of the promotion until its end, ensuring that all actions are synchronized and reliable. As with the other stages, scalability and resilience are key to handling large-scale promotions without errors.
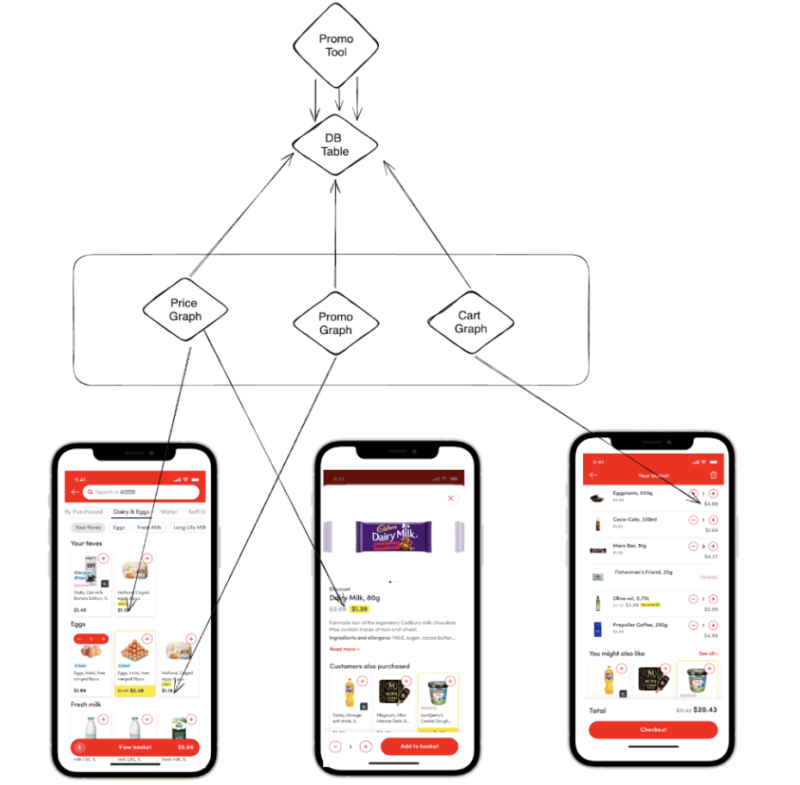
The Supergraph and Sub-Graphs
Although we’re implementing a supergraph architecture to highly improve the execution part of the above life cycle, this approach consolidates promo-related data into a single domain, streamlining processes and reducing inconsistencies.
We’ve introduced three sub-graphs within our supergraph: the Promo Graph, Price Graph, and Cart Graph. These handle active promotions, price updates, and cart management, respectively. However, there’s still work to do—such as unifying the data source to ensure that all three sub-graphs pull from the same place.
Entity Ownership
Every domain’s operations essentially involve products, making the Product entity our foundation. Ideally, the Product API should own this entity. However, other services also interact with this entity. The Product API should retain ownership of the content associated with the Product entity, while other services can utilize the product_id to access the product.
The ProductAPI will handle primary queries, while other services will identify the product and manage its sub-content. This establishes the ProductAPI as the main graph, with other services functioning as sub-graphs.
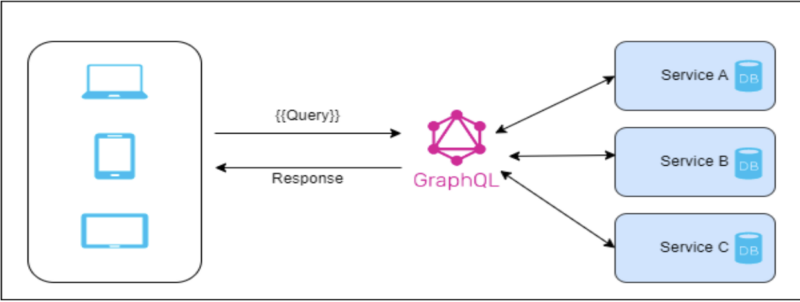
GraphQL Server
This service facilitates federation by identifying the primary service responsible for handling the main query and the services responsible for resolving specific entity fields within the request. It communicates with both the main graph and relevant subgraphs, consolidates the results, and presents them to the client. In this scenario, subgraphs only receive specific keys, such as product IDs, and provide the corresponding information.
Unified Data Source for Promotions
After consolidating all promotional data into a single database, we can ensure that promotions, prices, and carts are updated at the same time, which will guarantee data consistency between all three subgraphs:
Instead of storing promo items on the product level, we started to group them by SKU and campaign ID will allow us to scale efficiently, processing fewer entries while reducing the risk of inconsistencies.
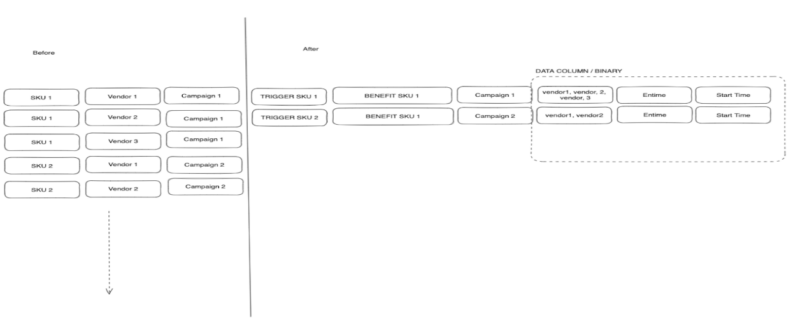
Schema
Our approach to benefits needed to be modified. Maintaining a product-based structure was not practical due to managers creating campaigns for each SKU and multiple vendors.
Under each row, the trigger SKU benefits SKU, and related campaign data are displayed. By shifting from a product-level focus to this more compact structure, we achieved a significant reduction in row count—in some instances, reducing 36 million rows to 1 million rows (a 97% decrease).
Storage Size
By utilizing a binary data column, we can store additional campaign information. This innovative approach enhances our ability to support future cases and enables us to store more information efficiently, optimizing storage space.
Caching
To reduce the load on the database, we have implemented a caching layer in each service. The data column, which is a binary column, can be large and may not fit in index pages. Therefore, if we fetch this row less often and store it in either memory (L1) or Redis (L2), it will give the database the flexibility to retrieve the data column faster when the load is lower. This optimization will enhance the overall performance and scalability of our system.
Eliminating Manual Campaign Start Events
One of the biggest improvements we’ve introduced is the ability to execute campaigns in real-time, without needing any actions for campaign start. This ensures that promotions will start and end exactly when they’re supposed to, without delays, since all the needed information is stored preprocessed and ready for immediate execution.
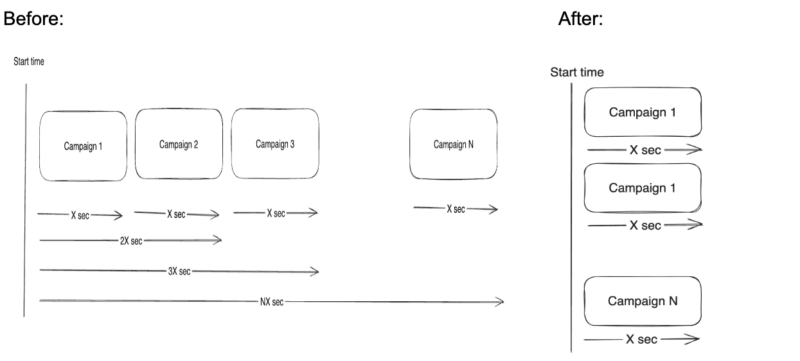
Increasing Promotion Processing Throughput
While the previous steps offer a solid foundation, one of our key objectives moving forward is to increase the throughput of promotion processing. The current system can handle around 500 products (single sku in a given vendor) per second, but we aim to drastically improve this to process up to 50,000 products per second. This increase in throughput will streamline how promotions are saved and activated, significantly reducing delays in large-scale promotions.
Addressing Bottlenecks
One of the major bottlenecks in promotion processing is the redundancy in data written to the database. For example, each product in a campaign is stored with associated data like vendor_id, vendor_code, and sku, which results in massive data duplication. This duplication not only increases the size of write operations but also impacts performance. By removing these redundant fields and normalising the data structure, we can reduce the load on the database and speed up the process.
Optimising Campaign Benefits and Triggers
Another area of improvement is the handling of campaign benefits and triggers. These components are currently stored in a way that causes unnecessary repetition of product and campaign data. By streamlining how campaign triggers are saved, we can reduce write times and improve overall processing efficiency. The goal is to ensure that campaigns with millions of products can be processed in under a minute.
A New Data Structure
To further enhance throughput, we plan to adopt a normalised table structure for campaign benefits and triggers. This new structure will remove redundant fields and use more compact data entries, which will not only reduce the size of the database but also improve query performance. This change will help us achieve the goal of processing promotions at 100x the current rate, making the system much more scalable and efficient.
Conclusion
As our promotions scale, we must handle massive datasets while maintaining accuracy and efficiency. By adopting a supergraph approach, unifying our data sources, and enabling real-time promo logic, we’re setting the stage for smoother, more reliable promotions execution at Delivery Hero, and we hope this can inspire other teams within our organisation.
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.







