



Knowledge discovery is vital for global companies like Delivery Hero. We developed EmployeeGPT to enhance knowledge sharing by scanning documents across platforms and languages, seamlessly integrating with daily workflows and communication channels.
The EmployeeGPT project originated from a simple need: finding specific information, like medical insurance coverage details in extensive documentation Typically this meant employees had to contact various teams, scan through multiple documents, or raise tickets, resulting in hours wasted. Similar scenarios come up frequently – whether it’s searching through technical documentation, product requirements or trying to stay updated on company news. While we have traditional solutions like organization-wide town halls and newsletters, these have limited reach due to language barriers and timezone differences.
EmployeeGPT is a Retrieval Augmented Generation (RAG) based bot integrated with internal communication tools such as Slack. It has evolved into a robust solution supporting various teams and geographical regions. The chatbot’s cross-platform capabilities allow it to combine data from sources like Google Drive, GitHub, and Confluence, providing comprehensive answers to user queries. It overcomes challenges by being asynchronous, language-agnostic, and updating its knowledge base regularly. It handles multiple languages seamlessly and is universally available at the click of a button. Let us now understand the details under the hood.
Overall Setup
EmployeeGPT is a modular setup with modules for data ingestion, user interaction and core module for interacting with a language model for query understanding and answer generation.
While a typical Large Language Model (LLM) is good at query understanding and formulating responses, it is not so good at staying grounded; rather, it hallucinates. Additionally, leveraging LLMs in real world applications presents latency challenges and cost concerns.
We leverage a Retrieval Augmented Generation (RAG) setup for mitigating hallucinations and periodic updates for knowledge base updates while keeping API costs under check. Figure 1 presents a high-level overview of the step.
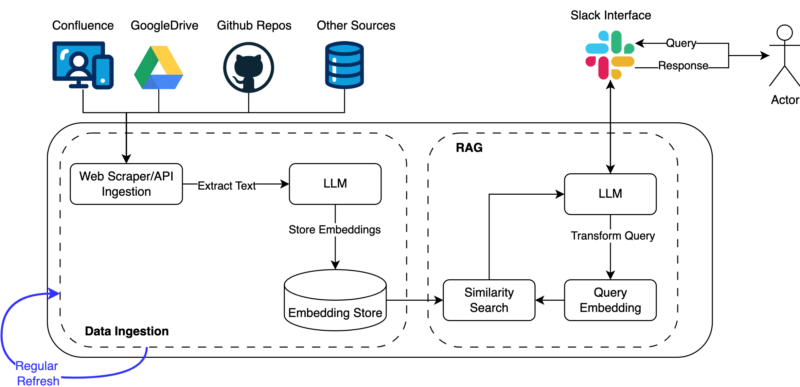
As shown in the figure, the ingestion engine is set to fetch updates every Sunday. It iterates through each individual knowledge platform (such as Confluence, GitHub, Google Drive, etc.) and converts them into embeddings that are understandable by the search algorithm.
These embeddings are stored in Bigquery which supports vector storage as well. For the user interaction part, an LLM Agent is hosted on Google Cloud Run, ready to listen for any query events that come up. Once an event is detected, it uses the user’s query to search for relevant documents to answer the question and then builds an answer to the question as a response.
Currently, the API endpoint is supported to work with Slack alone, but developments are underway to open up this endpoint to support more platforms such as the Dev Portal, the RFC bot and more.
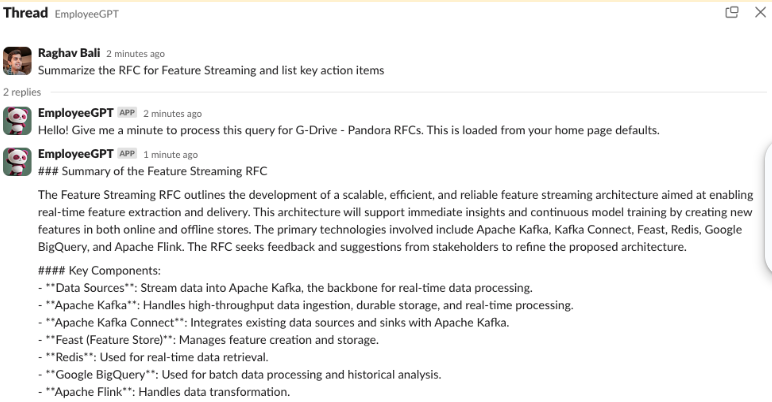

Another important aspect was to bake in references in the response to enable adoption and build trust. While several off-the-shelf commercial tools now offer such features, we had this feature from the beginning. As the bot can be invoked anywhere across Slack, with more integrations on the way, we provide an overall seamless experience to every employee.
Impact
As of June 2024, the bot has integrated with around 60 different spaces, repositories, and directories, encompassing 40 to 10,000 documents of various lengths, formats, templates, and languages. These documents cover a wide range of topics, including RFCs, onboarding materials, project documentation, and policies. In 2024 alone, the bot has answered approximately 6,000 queries, saving an estimated 500 man-hours (assuming 5 minutes saved per query).
Conclusion and Future Work
The LLM space is just heating up, and we are continually exploring new topics and optimizations to make EmployeeGPT even more efficient and effective. Beyond investigating newer LLM APIs, we are focusing on enhancing the RAG setup with more integrations, faster refresh rates, improved feedback and logging, better grounding, and advancements in prompt, retrieval, and storage.
The project so far has been supported by three of us in the data tribe. There’s been a lot of active interest and eagerness to contribute from across Delivery Hero. We are thrilled to be part of the InnerSource initiative which is an internal initiative for accelerating development and attracting experts from across Delivery Hero to drive improvements collaboratively.
If you like what you’ve read and you’re someone who wants to work on open, interesting projects in a caring environment, check out our full list of open roles here – from Backend to Frontend and everything in between. We’d love to have you on board for an amazing journey ahead.







