



S-Query is joint research work between Delivery Hero and Delft University of Technology (TU Delft) carried out by Jim Verheijde (TU Delft), Vassilios Karakoidas (DH), Marios Fragkoulis (DH), and Asterios Katsifodimos (TU Delft). The research paper appeared in this year’s International Conference on Data Engineering (ICDE’22), which consistently receives the highest rank in computer science research venues.
Stream processing systems process a potentially infinite stream of records continuously, and periodically output the results of their execution. Records signify flat structured data like database records. You can think of stream processing as the transposition of database queries. In database queries, data is static and queries are executed against it, while in stream processing, queries are static and data flows through them while being subjected to transformations. To satisfy the ever-increasing application requirements for scalable, efficient, and accurate data processing on the fly, modern stream processing systems are sophisticated distributed systems able to be deployed on hundreds of nodes and produce correct results with millisecond latencies while gracefully tolerating faults.
Many of the computations supported by stream processing systems, we shall call them streaming systems for brevity, are inherently stateful. The system is obliged to record the state of a computation because it is needed to produce a desired output. An example of a stateful computation shown below is an operator that sums and counts the records input up to that point to produce an average value, which it immediately emits. Although the state is recorded in main memory and is periodically checkpointed into reliable storage to survive failures, it is not exposed to applications, which only observe the periodic output of the performed transformations on the input data.
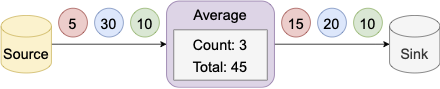
Exposing and querying the distributed state of a streaming system, which in short we refer to as queryable state, introduces novel use cases. Beyond analytics, streaming systems are used nowadays to serve machine learning models and run cloud applications based on microservices and stateful functions. For such operational use cases, the ability to query the distributed state of a streaming system in one shot offers a database view of its processing state, similar to what query interfaces offer in traditional database systems. For instance, an e-commerce application running on top of a streaming system would be able to join user accounts with purchases to determine sales grouped by user characteristics, such as age and gender. Lastly, queries to the state unlock debugging, auditing, and compliance use cases.
The problem of querying the state of distributed streaming systems externally presents important challenges in terms of overhead to the operation of the streaming system, correctness of query results, and scalable management of state sizes. First, streaming systems are susceptible to operational overhead given that they are designed and used for low-latency high-throughput processing. In fact, the processing they perform is continuous and it triggers continuous state updates. Thus, it is important that state access for answering an external query induces minimal overhead. Second, the correctness of query results under continuous processing also poses a challenge, especially for queries that combine different parts of a streaming system’s distributed state, which typically reside in remote hosts. Capturing a consistent view of the involved parts of the state requires aligning them in some way. The third challenge regards the size of the accumulated state over time, which can become considerably difficult to manage. The state size affects both query performance and the amount of space required for holding the state.
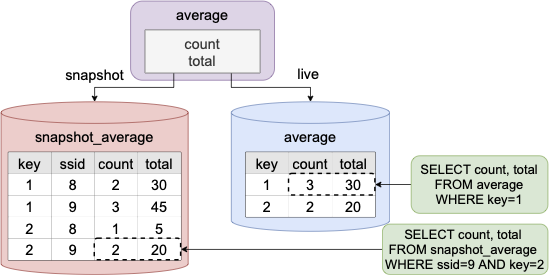
In response, we devised S-Query, an approach for querying the internal distributed state of a stream processing system, taking into account the above challenges. S-Query exposes the live state of a streaming system to external systems in a safe manner, thereby providing a fresh view of its live state. In addition, S-Query supports queries over the system’s snapshot state produced by periodic checkpoints, without obstructing the normal processing of the system. These two querying capabilities are complementary and can be very beneficial to external applications: live state queries offer a real-time view with no correctness guarantees, while snapshot queries produce consistent results over past states, but may be slightly outdated. The next figure depicts live and snapshot state queries on the state of the average operator. Finally, S-Query also offers optimization of snapshot queries based on incremental snapshots, which only record the differences with a previous snapshot.
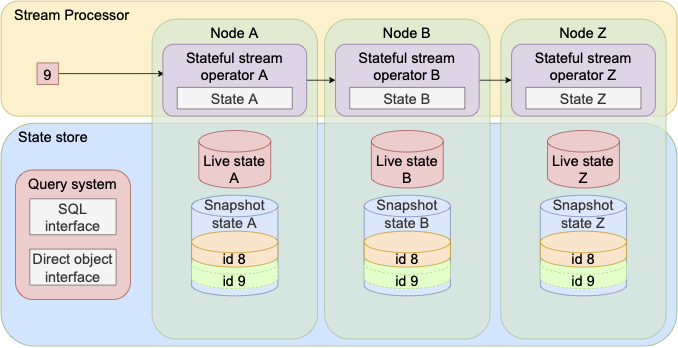
The figure below depicts the high-level architecture of S-QUERY. The architecture consists of two separate but tightly coupled systems: the stream processor which comprises a Directed Acyclic Graph (DAG) of stateful operators and the state store which is a partitioned database system, such as an in-memory key-value store like Hazelcast IMDG. Any change in the stateful operator state is directly reflected in the state store by S-QUERY and updates the live state stored there. At the same time, the state store holds the snapshots that are triggered by the checkpointing mechanism of the stream processor, which is used to snapshot the system’s state.
We implemented S-Query in Hazelcast Jet, a distributed streaming system that optimizes low-latency performance. S-Query is available as open-source software.
In Delivery Hero, we evaluated S-Query’s expressiveness and performance using four real queries on the state of a workload of online order and delivery events ingested by a Jet job, which accumulates state for rider locations, order statuses, and order information in each of the job’s operators respectively. We show queries 1-4 below. Each of the queries captures the need for a real-time ad-hoc view of the state of orders in the system that can guide on-the-spot business decisions and improve customer service. The data stream workload consists of the following events:
- Rider location includes the coordinates of the delivery rider with the latest update timestamp.
- Order status contains the state of an order, that is from ORDER_RECEIVED to PICKED UP to DELIVERED (and several other states omitted for space savings). It also includes a deadline when it should have transitioned to the next state.
- Order info is a one-time event per order containing general information about an order such as customer location, vendor location, and vendor category.
Query 1: How many orders are late (in preparation by the vendor for too long) per area? ======= SELECT COUNT(*), deliveryZone FROM "snapshot_orderinfo" JOIN "snapshot_orderstate" USING(partitionKey) WHERE (orderState='VENDOR_ACCEPTED' AND lateTimestamp<LOCALTIMESTAMP) GROUP BY deliveryZone;
Query 2: How many deliveries are ready for pickup per shop category? ======= SELECT COUNT(*), vendorCategory FROM "snapshot_orderinfo" JOIN "snapshot_orderstate" USING(partitionKey) WHERE (orderState='NOTIFIED' OR orderState='ACCEPTED') GROUP BY vendorCategory;
Query 3: How many deliveries are being prepared per area? ======= SELECT COUNT(*), deliveryZone FROM "snapshot_orderinfo" JOIN "snapshot_orderstate" USING(partitionKey) WHERE (orderState='VENDOR_ACCEPTED') GROUP BY deliveryZone;
Query 4: How many deliveries are in transit per area? ======= SELECT COUNT(*), deliveryZone FROM "snapshot_orderinfo" JOIN "snapshot_orderstate" USING(partitionKey) WHERE orderState='PICKED_UP' OR orderState='LEFT_PICKUP' OR orderState='NEAR_CUSTOMER' GROUP BY deliveryZone;
Experimental results
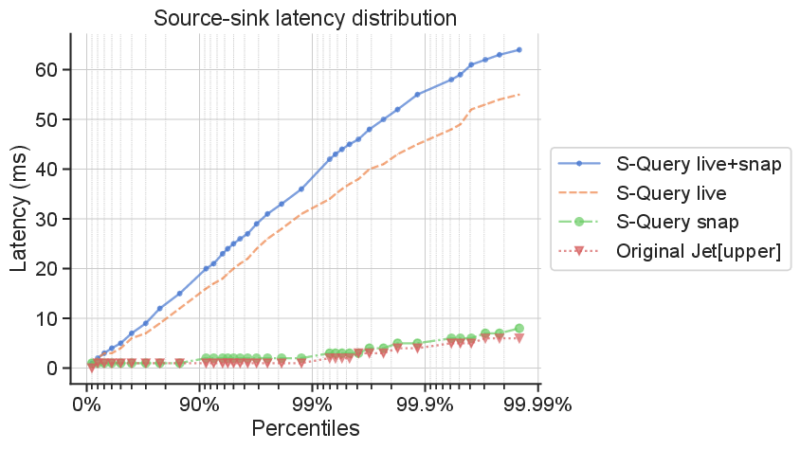
First, we evaluate the relative performance in terms of latency between live and snapshot queries using query 6 of NEXMark, the de facto benchmark of the stream processing domain. The experiment consists of four configurations, a) S-QUERY with both live and snapshot state enabled, b) S-QUERY with only live state enabled, c) S-QUERY with only snapshot state enabled, and d) Jet. The next figure suggests that the live state incurs significant overhead, which is to be expected since it amounts to communicating every single state change that happens at each operator of the system to the respective live state representation in the underlying state store, which is Hazelcast IMDG. The latency distribution of S-QUERY’s snapshot state configuration is almost identical to Jet’s configuration. For the rest of the experiments, we focus our evaluation on the snapshot state configuration.
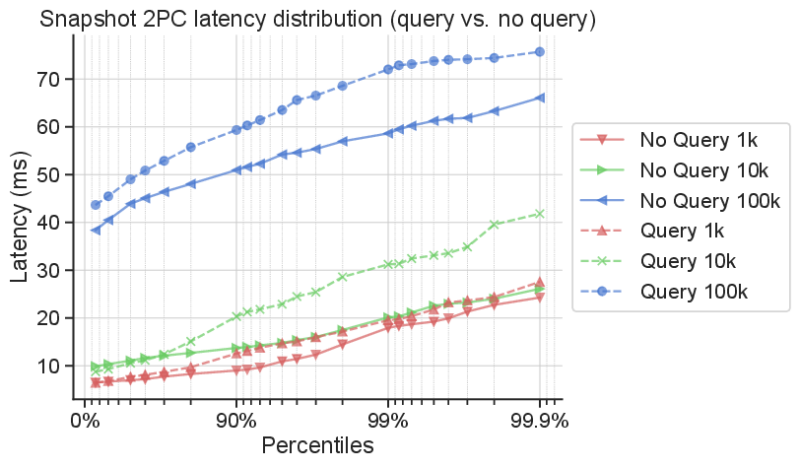
Next, we turn our attention to S-Query’s overhead to the system’s snapshot creation mechanism. We measure the latency distribution of the snapshot mechanism as before – with and without queries being executed on the snapshot state. For the experiments, we use Query 1, which is a relatively expensive query including both a JOIN and GROUP BY clause. The next figure shows the impact of queries on the snapshot PC latency. In general, the impact is up to 14ms across all unique key configurations. Notably, the time it takes to commit a snapshot is much smaller than the snapshot interval itself. Thus, consecutive queries from multiple threads do not affect the performance of a streaming job significantly.
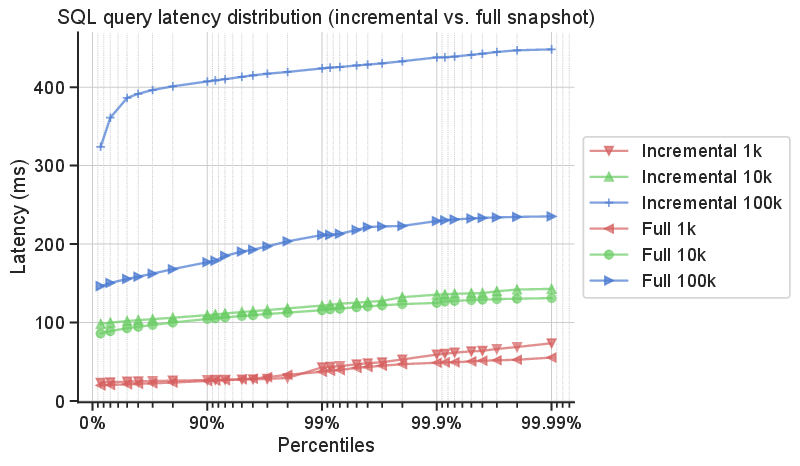
Finally, in the figure below we measure query performance for varying state sizes in terms of latency, which is quantified as the time it takes to execute a query and retrieve the complete result set. We use Query 1 in this experiment. As expected, the query execution latency increases with larger state size as a query has to process more state entries. Surprisingly, the performance of queries executed on incremental snapshots is identical to that of full snapshots for 1K and 10K unique keys, even though S-QUERY has to join all the incremental snapshots involved. That said, for 100K unique keys, queries on incremental snapshots manifest almost five times additional latency.
In summary, incremental snapshots present a tradeoff between savings in snapshot state size and overhead in query execution, and their use should be judged based on application requirements and the number of state changes introduced across keys.
To recap, S-Query is a novel approach supporting queries to the distributed state of a stream processing system. S-Query is able to query both the live and the snapshot state of a streaming system, providing complementary isolation levels, including serializable isolation, and performance characteristics. We evaluated the performance of S-QUERY on the NEXMark benchmark, as well as on a real workload from Delivery Hero SE, to find that S-Query adds little overhead to a streaming system when querying the snapshot state. S-Query is horizontally scalable and is able to perform tens to thousands of queries per second depending on query selectivity.
Marios Fragkoulis is the lead scientist of a research team dedicated to boosting innovation across Delivery Hero by solving challenging problems with high impact. Currently, the team is tackling problems in the recommender systems space. Marios can be contacted at marios.fragkoulis@deliveryhero.com.
Interested in working with us? Check out some of our latest openings, or join our Talent Community to stay up to date with what’s going on at Delivery Hero and receive customized job alerts!




