



In this article, we hope to display how we run a part of our AWS computing fleet on Spot Instances at Delivery Hero. Delivery Hero aims to have a substantial area of the business running on Spot instances by the end of Q2.
As you may know, EC2 Spot instances on AWS can help you save up to 90% compared to On-Demand prices. Delivery Hero is growing constantly, therefore this solution helps us to lower the pace of the growing costs of the overall infrastructure, and increase profitability.
The main goals of this solution are:
- Control the percentage of Spot instances on the fleet.
- Use Kubernetes native mechanisms as much as we can to avoid maintaining custom solutions.
- Be compatible with the EKS environment, as it is the solution we use for our Kubernetes clusters.
- Be able to use self-managed node groups, needed to implement dedicated workload.
- Improve our cost efficiency, allowing workload to run on Spot instances.
- Define a fallback mechanism to avoid compromising the high availability of the services.
What is the big picture of the design?
We run Kubernetes clusters on Amazon EKS with at least two Auto Scaling groups (ASG). The first one is the fallback called ASG On-Demand, and as its name indicates, it runs all instances on demand. The second one is a mixed ASG of Spot and On-Demand instances. We will refer to this as the ASG Spot.
On the Kubernetes side, we also need some key components. First, a service that scales the ASG when needed. For this task, we use the cluster-autoscaler. Second, we need a service that detects and processes the termination calls and performs draining of the node. This signal is sent by AWS two minutes before a Spot Instance is terminated. For that we use the AWS node-termination-handler.
Here is a quick overview of the architecture:

Configuring the environment
Autoscaling Groups
The ASG Spot needs to be configured to create Spot and On-Demand instances, including a taint which would not allow pods to be scheduled by default. Both ASG’s need a Kubernetes Node label called “asg-lifecycle” to specify if the node comes from the ASG Spot or the ASG On-Demand.
Also, in the instance’s user-data, we use the instance’s metadata to get the lifecycle of the node and include this value as a node label when it is registered in Kubernetes. This label will be called “lifecycle”. This label will help us distinguish Spot instances from On-Demand instances, in order to control which node should be scheduled.
### User Data ###
aws_az=$(curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone)
aws_region=$${aws_az%%?}
aws_instance_id=$(curl -s http://169.254.169.254/latest/meta-data/instance-id)
aws_instance_lifecycle=$(curl -s http://169.254.169.254/latest/meta-data/instance-life-cycle)
aws ec2 create-tags --resources $aws_instance_id --region $aws_region \ --tags Key=Lifecycle,Value=$aws_instance_lifecycle### Kubelet Registering Command ###
--kubelet-extra-args \ --node-labels=node.kubernetes.io/lifecycle=$aws_instance_lifecycle \
--register-with-taints=node.kubernetes.io/lifecycle=spot:NoScheduleEKS Cluster
Cluster-autoscaler is configured with priority expander in order to set a higher priority for nodes launched by the ASG Spot, rather than the ASG On-Demand.
Aws-node-termination-handler is deployed as a daemonset on every Spot node, in order to detect their termination calls and perform a draining of the node. The node label lifecycle is used to determine the type of instances to run this daemonset.
Every pod meant to run on Spot nodes is configured to include a nodeAffinity of type preferredDuringSchedulingIgnoredDuringExecution that points to the Node label “asg-lifecycle” and a toleration to satisfy the Spot instance’s taint that prevents any regular pod to be scheduled.
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key:asg-lifecycle
operator: In
values:
- spot
weight: 30
tolerations:
- effect: NoSchedule
key:asg-lifecycle
operator: Equal
value: spotThe main reason behind this architecture is to run any pod in the cluster on Spot instances, but to also allow them to run on On-Demand nodes when on the spot nodes cannot be scheduled.
At this point, our architecture is almost complete but we face a certain challenge: cluster-autoscaler does not consider soft constraints, therefore nodes from the ASG Spot would be less frequently triggered. In order to alleviate this problem, we also added a deployment of cluster-overprovisioner to our fleet, which will force the ASG to increase the available number of Spot instances in the cluster and keep them on standby until they are needed. Accordingly, we included a nodeAffinity in the deployment to trigger the ASG Spot.
With this implementation, we can encounter one of the following scenarios when our cluster changes its size.
Scenario one
A new pod is configured with nodeAffinity and tolerations to run on Spot Instances. Then it starts looking for a Node to be allocated in.
Cluster-autoscaler detects that there is no more space available in the Cluster and tries to find a Node pool to create the new Node in.
The ASG with the highest priority, in this case the ASG Spot, is the first option, and since the pod includes a toleration for the Nodes registered by this ASG Spot, cluster-autoscaler will not keep looking for any other match and will immediately ask for a new Node.
AWS accepts the Spot request and once the new Instance is ready and has joined the cluster, the Scheduler identifies there is more space in the cluster to allocate pods. Then, the Scheduler take in consideration the preferredDuringSchedulingIgnoredDuringExecution of our pending pod to allocate it into the newly joined Spot node.
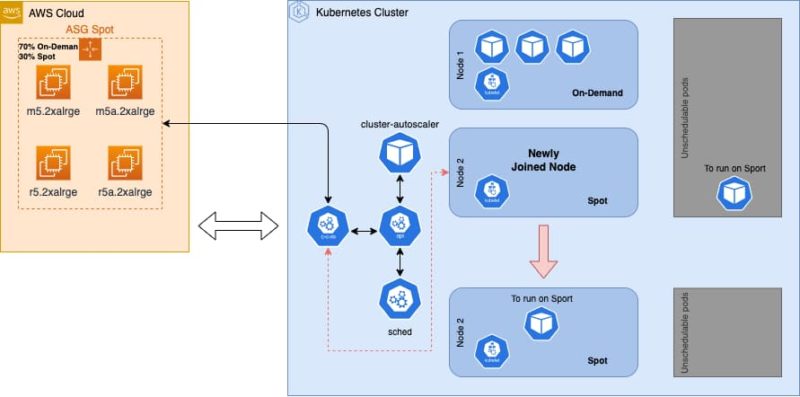
Scenario two
Same as in scenario one, a new pod is configured with nodeAffinity and tolerations to run on Spot Instances and is looking for a node to be allocated in. But in this case there is no Spot capacity available from AWS, so this will cause a failover to the On-Demand ASG.
Cluster-autoscaler detects that there is no more space available in the cluster and tries to find a node pool to create the new node in.
The ASG with the highest priority, in this case the ASG Spot, is the first option and since the pod includes a toleration for the nodes registered by this ASG Spot, cluster-autoscaler will not keep looking for any other match and will immediately ask for a new Node.
As mentioned before, AWS has no capacity for Spot available at this time, therefore, AWS rejects the Spot request. This will cause Cluster-autoscaler to automatically retry the creation of the new Instance from another configured node pool. Based on priorities, a new node will be requested to the ASG On-Demand.
Once the new instance has joined the cluster, the kube-scheduler identifies there is more space in the cluster and since our pending pod is only using a soft constraint in the node affinity, the kube-scheduler proceeds to assign the pod into this newly created On-Demand node.
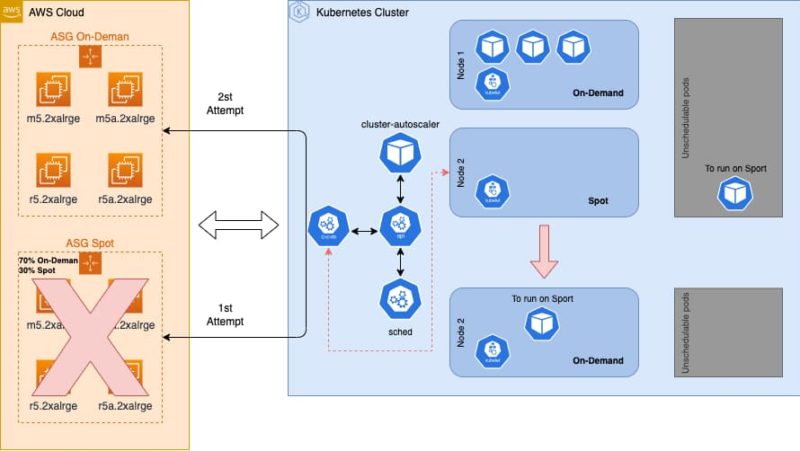
Scenario three
In this last scenario, multiple Spot instances are deleted, triggering a high demand for instances in AWS.
In this case all those nodes are drained and pods are reallocated to other nodes with sufficient compute resources available.
When the cluster runs out of resources, some pods are marked as unschedulable. As a result of this, cluster-autoscaler triggers new nodes to be created from the ASG Spot.
Since there are many simultaneous requests for nodes, the ASG Spot takes some time to fulfill them all, causing cluster-autoscale to timeout and retry to create more nodes from the next available node pool, in this case ASG On-Demand.
When all nodes from the ASG Spot and ASG On-Demand are ready and have joined the cluster, the remaining pending pods get scheduled.
This architecture ensures the availability of compute resources at all times, even when large numbers of Spot instances are terminated, or during big scaling events. However, we discovered an issue with this solution.
With time and the termination of more and more Spot instances happening on a daily basis, we noticed the workload gradually switching from Spot instances to On-Demand. This happens as a result of the On-Demand instances being available for longer periods of time than the Spot instances, which over time, causes the cluster to have more available space fulfilled by new On-Demand instances than Spot instances when these are terminated.
This could potentially be addressed in multiple ways, and Delivery Hero decided to do it by creating a software that would identify pods that could potentially be rescheduled on available Spot Instances in the EKS Cluster.
Improving the solution
The reason why pods were to be scheduled on On-Demand instances rather than Spot instances is directly related to the unavailability of resources provided by these last ones, while there is plenty of spare capacity provided by On-Demand Instances within the cluster.
These extra available On-Demand resources cause the kube-scheduler to not request a new Spot node.
By the time new Spot instances join the cluster, many pods have probably already been scheduled on On-Demand instances,which are less likely to be suddenly evicted. It’s then when the introduction of a software which can look for those pods and reschedule them can improve the situation and help rebalance the workload back to Spot instances.
At the moment, there is no such capability in any of the already existing open source projects out there, and changes on the native scheduler config is not possible yet when using EKS because the Kubernetes Scheduler is one of the components of the control plane, and it is managed by AWS. That’s why Delivery Hero’s Infrastructure team decided to build their own in-house tool which would fulfill this requirement.
The built tool is meant to address the situation by looking for pods that are running on nodes that do not fulfill their nodeAffinity, and that can potentially be rescheduled, and then check the availability on nodes which fulfill that constraint. For every pod found that passes the checks and matches the criteria, the software performs an eviction. This forces the pod to be rescheduled by the kube-scheduler again, which at this time, should be able to find available resources from a node which fulfills all the preference conditions. In this case, a Spot instance.
Karpenter
Finally, we also would like to add that we are looking into Karpenter, which is an open-source, flexible, high-performance Kubernetes cluster autoscaler by AWS. The main difference is that Karpenter schedules EC2 instances directly, without using any ASGs under the hood, which can reduce the complexity of the solution, and potentially can observe the state of each node and make decisions to launch new nodes and terminate them to reduce scheduling latencies and infrastructure costs, that probably can remove the need of the in-house tool to reschedule pods allocated on wrong nodes.
Karpenter looks promising for a next step, but at the moment it still misses the possibility to control the percentage of the fleet that runs on Spot instances. We also need to be in control of the scenario where there are no more Spot Instances available, that are key for reliability. Karpenter implementers failover to On-Demand in cases when there is no Spot capacity available. But it also has the same problem where these nodes are not automatically replaced when Spot capacity is available. A workaround suggested by AWS is to implement node TTLs to terminate nodes after they exceed a certain age, which can be also configured on Karpenter.
In summary
I hope that I have conveyed to you in this article how Spot instances can be implemented on production workloads, in order to reduce infrastructure cost without compromising the reliability and stability of the system all this by taking advantage of the self-healing properties of Kubernetes.
After the implementation is rolled out, you can increase the percentage of the fleet that runs in Spot and adjust the settings according to your needs. Here at Delivery Hero, we will continue to explore solutions like Karpenter, that potentially reduce complexity and bring about the results that we are looking for.
Thank you for sharing these insights with us Miguel & Giovanny!
We are still hiring, so check out some of our latest openings, or join our Talent Community to stay up to date with what’s going on at Delivery Hero and receive customized job alerts!






